- Wachter Space Blog about Security and Automated Methods/
- Posts/
- Machine Learning for Computer Security at KIT/
Machine Learning for Computer Security at KIT
Table of Contents
Overview #
Topics from the lecture. I use mind maps like this before exam preparation to see what I can remember from during the semester. During learning, I expand on the topics. Later I use color coding of the nodes to visualize what topics I know well and what still need practice.
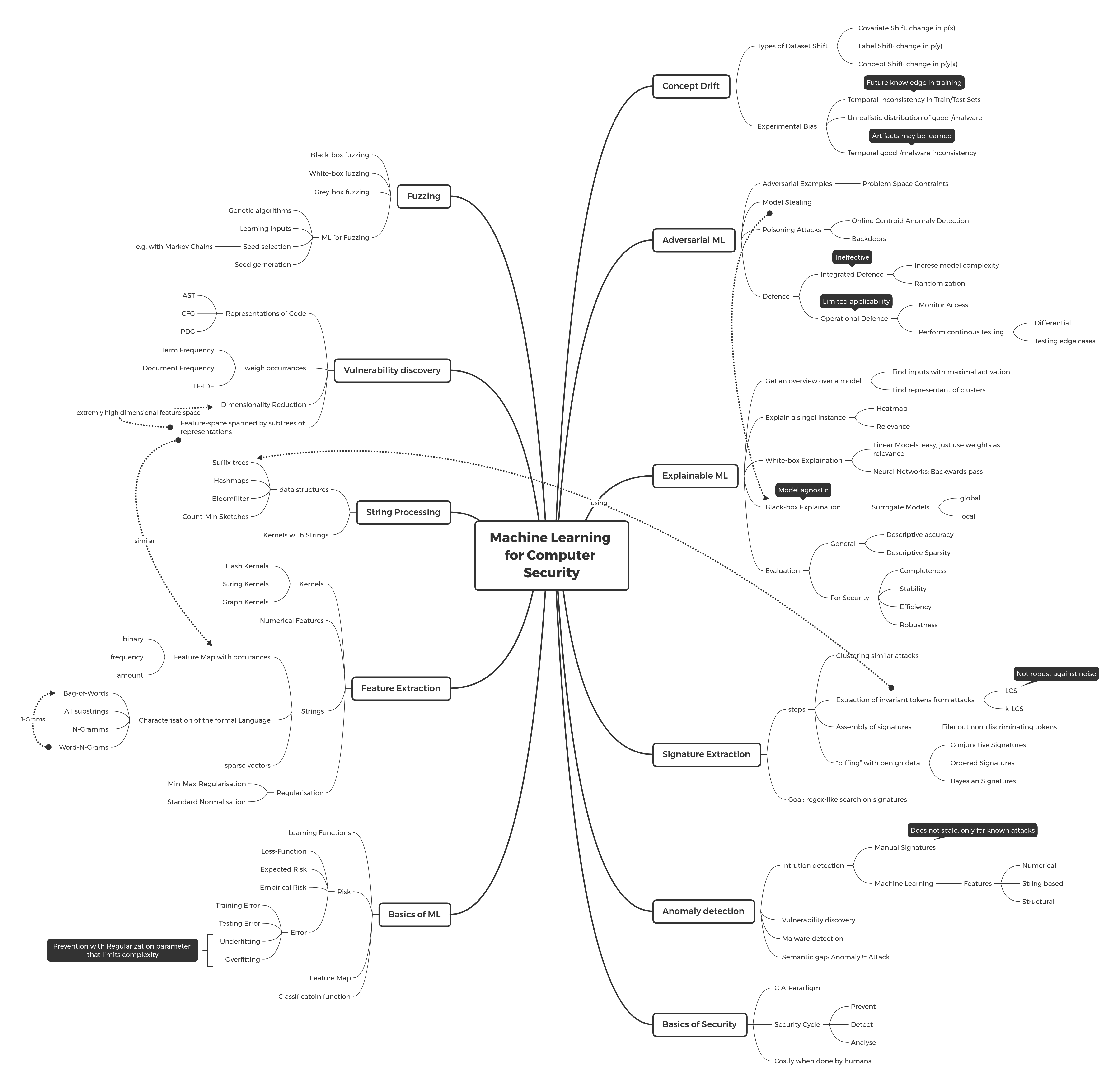
I also made an Anki deck. But sadly the deck contains screenshots of slides that are not licensed under a free licence.
Exam practice questions #
Introduction #
What are the three main security goals?
(click to view answer)
Confidentiality, Integrity, Availability. CIA-Paradigm. General goals, specific specification required. Other security goals outside of the CIA-Paradigm are thinkable.Describe the inverse feature-mapping problem.
(click to view answer)
Using a feature mapping function it is easy to map a sample from problem space into feature space. Though it is hard or in some cases even impossible to invert this function i.e. reconstructing the original sample given just the feature vector. This makes it in some cases hard to generate adversarial examples.What is part of the “Security Cycle”? Why is there an imbalance? Name one general technique from the lecture that helps to counter that imbalance. Where in the security cycle does it help?
(click to view answer)
Prevention, Detection, Analysis. There is much more new malware/attacks (with high diversity) than capacity of human analysts, therefore automation is needed. One type of automation that requires very little human assistance is fuzzing. Fuzzing is primarily used for vulnerability discovery. The aim is to find vulnerabilities before attackers do, so it fits to prevention.Name challenges of Machine Learning for Computer Security.
(click to view answer)
Effective: Good detection rate with few false positives (false alarms), Efficient: Being able to process large amounts of data, Robust: No corner cases or evasion attacks must be missed.Machine Learning 101 #
What is a training and a testing set. What is the important requirement for these sets?
(click to view answer)
A machine learning model is trained (i.e. its parameters are adjusted) on training data. Later the model is evaluated on testing data. It is important for those datasets to be disjoint. Also for temporal data the training data must be the older than the testing data. Otherwise we are “learning the future and predicting the past”. More requirements for the domain of computer security are in the lecture about concept drift.What is loss? Name 3 loss functions. For which kind of learning problem can the hinge loss be used? How must the labels be set to achieve meaningful loss with this function?
(click to view answer)
Hinge-Loss \[L\left(f_{\theta}(x), y\right) \mapsto \max \left(0,1-y \cdot f_{\theta}(x)\right)\] 0-1-Loss \[L\left(f_{\theta}(x), y\right) \mapsto\left\{\begin{array}{ll} 0 & f_{\theta}(x)=y \\ 1 & f_{\theta}(x) \neq y \end{array}\right.\] Quadratic-Loss \[L\left(f_{\theta}(x), y\right) \mapsto\left(f_{\theta}(x)-y\right)^{2}\] Hinge-Loss depends on the labels being -1 or 1.What is underfitting? What is overfitting? Give an example of how to constrain the complexity of a model.
(click to view answer)
Underfitting means having a model so simple and generic that it is not able to predict new data. Overfitting means having a model so complex that it is so adjusted to the training data that it is not able to predict new data. The naive optimization problem would just try to minimize the empirical risk: \[\underset{\theta\in\Theta}{\mathrm{argmin}} \, R_n(f_\theta)\] To prevent overfitting, which the naive optimization problem would lead to, a complexity term is added. So the new optimization problem becomes: \[\underset{\theta\in\Theta}{\mathrm{argmin}} \, R_n(f_\theta) + \lambda C(f_\theta)\] The parameter λ is there to find the “sweet spot” between over- and underfitting.What is risk? How is expected risk defined? How can it be approximated?
(click to view answer)
Risk is the cumulative loss. Expected risk is the loss cumulated over the whole input distribution. \[R_\infty(f_\theta) = \int L(f_\theta(x),y)\, dP(x,y)\] As in practice this distribution is unknown it can be approximated with empirical risk which is calculated on known labeled data. \[R_n(f_\theta) = \frac{1}{n}\sum_{i=1}^{n}L(f_\theta(x_i),y_i)\]Does low empirical risk imply low expected risk? What issue can arise? How can this issue be mitigated?
(click to view answer)
No, it does not. Expected risk is taking all possible inputs into account whereas empirical risk only takes the known inputs into account. A model might be overfitted meaning that it performs well on known data but bad for new data. Using a regularization term to limit the complexity of the model as well as having a representative (for the input distribution) selection of samples leads a better approximation of the expected risk.Given a set $A=X\times Y$ of samples with labels. Explain what k-fold cross validation is. Draw a sketch for $k=4$.
(click to view answer)
To adjust parameters of a model the training dataset is split in k equally sized parts. For each set of parameters k runs are conducted. For each run the kth set is the validation set to see how well the chosen parameters work. In the end the set of parameters with the best average results are used. It is important to note that this is strictly separated from testing data.Are XOR, AND, OR linearly separable? Why or why not?
(click to view answer)
XOR is not linearly separable. From looking at the 2d plot it becomes clear that one linear decision boundary cannot separate the data, as the classes lie in between each other. AND and OR are linearly separable. Here 3 of four samples belong to the same class (and are not linear depended) so they can be “cut off” by a linear function.Name the two main learning model concepts. What are the differences? In the context of Security, what are typical applications of each?
(click to view answer)
Discriminative models and Generative models. Discriminative models classifies samples using a decision function. Generative models can generate new samples by modelling the underlying concepts. The first typically uses supervised Learning trains a model with labeled data, meaning data for which the true classification is known. The latter often uses unsupervised learning. Here labels are not known. In the context of security supervised learning is for example used for malware classification. Supervised learning is for example used for intrusion detection because it is hard to find representative labeled data for intrusion and it also often not possible to be sure that the current observed activity is purely benign.From Data to Features #
How are strings mapped to feature space? How is the mapping function defined? What are methods for coming up with a formal language for this mapping to work?
(click to view answer)
Given a formal language the feature map is defined with the occ function that indicates the occurrence of a word in the sample at hand. The occ function can describe binary occurrence, number of occurrences or frequency. Formally the feature map is defined as: \[ \phi(x)=(w_s \cdot occ(s,x))_{s_\in L}\]What are advantages and disadvantages of feature hashing?
(click to view answer)
Feature hashing allows mapping non-numerical aspects to feature space without coming up with a sophisticated mapping. Of course there is the risk of collisions. In practice a hash function of size 2^20 to 2^24 is often enough for good results. With this size the number of dimensions is also practically small. Another downside is that small derivation (of e.g. continuous aspects) lead to completely different values.What are the advantages of normalizing data (in the context of features)? Give formulas of two different approaches.
(click to view answer)
Data is normalized in order to have a uniform domain of features for all aspects as their scaling and offset often differ. Without normalization learning might be biased to few dominant features. The normalization techniques presented in the lecture are: Standard normalization: \[ \frac{\phi_i(x)-\mu_i}{\sigma_i} \] Min-max normalization \[ \frac{\phi_i(x)-min_i}{\max_i - \min_i} \]Describe different methods of processing strings for feature extraction. Name at least one where knowing a delimiter character is required and one where this is not required.
(click to view answer)
With knowing the separation character: Bag of words (word-1-grams): Obtain the tokens simply by splitting at the separation character. This is straightforward but contextual information is lost. Word-n-grams: Extract all sequences of n words (a word is separated with the delimiter character). Without knowing the separation character: All substrings: Use all substrings from a string. This method is straight forward with no parameters and retains contextual information but leads to high redundancy and a lot of tokens. n-grams: Extract all substrings of size n.What properties does a function need to have in order to be considered a kernel?
(click to view answer)
No, a kernel must be positive semi-definite and symmetric. The function signature is: \[k:X\times X\to \mathbb{R}\]Show that $$|| \phi (x) - \phi(z)||_{2} = (k(x, x) + k(z, z) - 2k(x, z))^{0.5}$$
(click to view answer)
According to Mercers Theorem there exists a (implicit) map from problem to feature space such that: \[k(x,z)=\sum_{i=1}^n\phi_i(x)\phi_i(z)\] Therefore \[(k(x, x) + k(z, z) - 2k(x, z))^{0.5}\] \[= (\sum_{i=1}^n\phi_i(x)^2 - 2\cdot\sum_{i=1}^n \phi_i(x)\phi_i(z) + \sum_{i=1}^n\phi_i(z)^2)^{0.5}\] \[= (\sum_{i=1}^n \phi_i(x)^2- 2\phi_i(x)\phi_i(z) + \phi_i(z)^2)^{0.5}\] \[= \sqrt{\sum_{i=1}^n(\phi_i(x)-\phi_i(z))^2} = || \phi (x) - \phi(z)||_{2} \]What makes a kernel function so useful?
(click to view answer)
We can use algorithms for linear separation that make use of the inner product of features for not linearly separable data by using the right kernels. Because according to Mercers Theorem a kernel function k induces an implicit feature mapping. \[k(x,z) = \langle\phi(x),\phi(z)\rangle\] Also there are kernels that imply a infinite dimensional feature map.Compute the similarity score of “implementation” and “installation” with n=2 grams and the dot product.
(click to view answer)
Fora="implementation" the 2-grams are A={im,mp,pl,le,em,me,en,nt,ta,at,ti,io,on} and for b="installation", B={in,ns,st,ta,al,ll,la,at,ti,io,on}. With a binary occurrences function and a standard weight vector:
\[\langle\phi(a),\phi(b)\rangle=\sum_{s\in A\cap B}\mathrm{occ}(s,a)\mathrm{occ}(s,b)=5\]
Why are numerical features often not sufficient in the context of computer security?
(click to view answer)
It is hard to capture structural aspects as numerical features, as some aspects might be missed and is not possible to represent complex relations of elements in the structure.String Processing #
Explain what a count-min sketch is. How are values inserted? How are values retrieved? What guarantee is there to the values retrieved?
(click to view answer)
A Count-Min Sketch is a set of hash functions that map in separate arrays. That approximately counts the number of inserted objects. Inserting works by: \[insert(x): A_1[h_1(x)]\texttt{++},\ldots A_n[h_n(x)]\texttt{++}\] Retrieving values works by: \[get(x)=\min(A_1[h_1(x)]\ldots A_n[h_n(x)])\] This guarantees to never under approximate values.What is the difference between a Bloom Filter and a Count-Min-Sketch?
(click to view answer)
Both have n hash functions, but for a bloom filter those map to one array and for a Count-Min-Sketch to n arrays. The bloom filter approximates the binary indicator: “Was an object inserted in the bloom filter?”, the count-min-sketch approximately counts how many of the same object were inserted.What makes suffix trees the swiss army knife of string analysis?
(click to view answer)
Suffix tree can be constructed in linear time and are used in many string processing algorithms. For example for LCS, KLC and string kernels.Why is LCS not a good idea to use on a real world dataset? Explain with an example. What would be a better method?
(click to view answer)
When working with noisy data (e.g. error in clustering or incomplete attacks) it might be the case that a great majority (e.g. N-1 samples) have a long common sequence but the result is a much shorter as it is not present in the rest. Example:- A common sequence
- noise
- A common sequence
- A common sequence
Name three different kinds of signatures.
(click to view answer)
Conjunctive signatures, bayesian signatures, ordered signaturesName at least one way in which an attacker can make the signature generation algorithm less effective.
(click to view answer)
The attacker can try to poison the learning dataset if possible by injecting characteristics from one class in the other. Also the attacker can use fake long and invariant tokens that do not contribute to the malicious behaviour and therefore are easy to change on a regular basis.What are common steps towards creating signatures?
(click to view answer)
- Cluster attacks
- Extract invariant tokens
- Filter for discriminative tokens
- Assemble signatures that can be matched against new data
Are signatures robust?
(click to view answer)
No they are not, see previous answer:The attacker can try to poison the learning dataset if possible by injecting characteristics from one class in the other. Also the attacker can use fake long and invariant tokens that do not contribute to the malicious behaviour and are therefore easy to change once the attacker thinks that signatures were extracted.
Anomaly Detection #
Briefly explain the three/four types of features presented in the lecture
(click to view answer)
Numerical features such as length and entropy, String features such as a binary protocol, structured data such as ASTs or Code Property Graphs.Given a one class SVM, $X$ a set of benign data, $\mu$ the center of the hyper-sphere. State the optimization problem. What would you do in the real world to make this robust against outliers? Explain referencing the optimization problem.
(click to view answer)
The optimization problem is: \[\min \, R^2,\,||\phi(x_i)-\mu||^2\leq R^2\] The problem here that outliers force the hyper-sphere to be very large. The solution is to add slack variables that allow some benign samples to be a certain distance outside the hyper-sphere. The new optimization problem is: \[\min \, R^2+C\sum_{i=1}^n\xi_i,\,||\phi(x_i)-\mu||\leq R^2+\xi_i,\,\xi_i\geq 0\]How does the regularization parameter in SVM affect the decision boundary?
(click to view answer)
A low regularization parameter leads to a soft decision function. Whereas a high regularization parameter leads to a sharp decision boundary.Describe three different approaches for learning-based attack detection.
(click to view answer)
Modelling benign data only, modelling malware only, learning the difference between benign and malicious activityWhat assumptions are made for anomaly detection?
(click to view answer)
We are modelling normality and detection deviations therefrom. This is a semantic gap to the detection of malware. Most of the time we don't have labeled data, especially not of attacks. Therefore we resort to unsupervised learning on a dataset where the large majority is benign.What geometric algorithms have we seen for modeling normality?
(click to view answer)
Center of mass, one class SVMs, Center of NeighborhoodFirst give the formula which describes the global model of normality as a center of mass. Then explain in a few words what it intuitively means.
(click to view answer)
For the center of mass we are calculating the average of all samples of a class. \[\mu = \frac{1}{n}\sum_{i=1}^{n}\phi(x_i)\] Then we choose a radius around that point so that all samples are enclosed in the hypersphere. Samples outside that radius are then classified as not normal.Give the formula to explicitly compute the anomaly score by distance from the center.
(click to view answer)
\[||\phi(x)-\mu||^2\]What are drawbacks of signatures?
(click to view answer)
Signatures are rather easy to change. For example by renaming, restructuring and changing some data types. So they are not useful for novel attacks or even just smaller variations of malware. Also there is a delay until new signatures are available for the end user. Therefore signatures do not scale with complexity and number of attacks.Show that: $$||\phi(z)-\mu||^{2}=k(z, z)-\frac{2}{n} \sum_{i=1}^{n} k(z, x_{i})+\frac{1}{n^{2}} \sum_{i, j=1}^{n} k(x_{i}, x_{j})$$
(click to view answer)
Using the basic properties of the dot-product and Mercers Theorem: $$\begin{aligned} \left\|\phi({z})-\mu\right\|_{2}^{2} &=\left\langle\phi({z})-\frac{1}{n} \sum_{i=1}^{n} \phi\left({x}_{i}\right), \phi({z})-\frac{1}{n} \sum_{i=1}^{n} \phi\left({x}_{i}\right)\right\rangle \\ &=\langle\phi({z}), \phi({z})\rangle-\frac{2}{n} \sum_{i=1}^{n}\left\langle\phi({z}), \phi\left({x}_{i}\right)\right\rangle+\frac{1}{n^{2}} \sum_{i, j=1}^{n}\left\langle\phi\left({x}_{i}\right), \phi\left({x}_{j}\right)\right\rangle \\ &=k({z}, {z})-\frac{2}{n} \sum_{i=1}^{n} k\left({z}, {x}_{i}\right)+\frac{1}{n^{2}} \sum_{i, j=1}^{n} k\left({x}_{i}, {x}_{j}\right) \end{aligned}$$Malware Classification #
What assumptions do we make when it comes to classification for attack detection?
(click to view answer)
We cannot model malware in general. Therefore we need a large and representative samples from both benign programs and known attacks. For benign samples we model normality and can detect deviations. Mind the semantic gap! This is does not mean that we are detecting malware. For malware, we assume that new attacks share similarity with old attacks.For malware classification using machine learning you need a lot of samples. Name resources where to get them from?
(click to view answer)
Search the wild wild internet :), manual analysis, findings of virus scanners, online repositories such as virus total. The problem with all the sources is that they are in no way representative and not all of them come with labels.Define the decision function of the perceptron as well as the perceptron rule for learning.
(click to view answer)
The perceptron adjusts its weights and its bias by trying to find a linear separation between the classes. It goes trough all labeled samples, for wrong classifications it adjusts its weights to move the boundary in the direction of the sample by decrementing of incrementing of the weight. \[w=w+y_{i} \phi\left(x_{i}\right) \quad y_{i} \in\{\pm 1\}\] This only converges if the data is linearly separable. The classification is straight forward: \[\mathrm{sgn}(\langle w, \phi(x_i)\rangle + b)\]Define the decision function of SVMs and the two-class SVM optimization problem. Define the extended optimization problem which deals with non-linearly separable data.
(click to view answer)
The decision function of a one class SVM is: \[\mathrm{sgn}(\langle w, \phi(x_i)\rangle + b)\] For a two-class SVM the optimization problem is: \[\min_{w,b}\,||w||,\, y_i\langle \phi(x_i),w\rangle + b \geq 1 \quad (i = 1,\ldots, n)\] For non linearly separable data we either try different kernels or we introduce slack variables. \[\min_{w,b} \,||w||+C\sum_{i=1}^n\xi_i,\,y_i \langle\phi(x_i),w\rangle + b \geq 1-\xi_i,\,\xi_i\geq 0\]Give examples of attacks against classification methods.
(click to view answer)
- Poisoning of learning: Careful injection of malicious or benign data
- Mimicry during detection: Adaptation of attacks to mimic benign activity
- Red herring: Denial-of-service with bogus malicious activity
Why is the term “support vector” included in Support Vector Machines. Which drawbacks come with it?
(click to view answer)
The samples on the edge of the decision boundary (or the margin line) of a SVM are called support vectors. The support vectors determine the position of the decision boundary. The drawback is that this is not resistant against outliers.What is the difference between a one-class and a two-class SVM? Which is used for what?
(click to view answer)
A two class SVM tries to separate two classes of data from each other by finding a decision boundary with maximum margin. (Usage: Learning the difference between malware and goodware). A one class SVM decides if a given data point is similar to learned data. I.e. if it belongs to that class. In the lecture this was characterised as a hypersphere enclosing all learned data points. (Usage: Modelling normality, which allows to see if a given sample is similar to learned benign samples.)Concept Drift #
What is concept drift?
(click to view answer)
Concept drift, more generally referred to as dataset shift, is defined as having a different distribution of training and testing data.What are the main types of dataset shift? Give one example for each. State the changing distribution.
(click to view answer)
- Covariate shift. Change in the distribution of p(x) E.g. the usage of a api method.
- Label shift. Change in the distribution of p(y). E.g. more/less malware in circulation.
- Concept shift. Change of the distribution of p(y|x). E.g. SEND_SMS is now also widely used by benign apps.
What are possible approaches to deal with dataset shift (especially if caused by a non-stationary domain)?
(click to view answer)
Active Learning and Incremental RetainingWhat is the confusion matrix? Define precision and recall.
(click to view answer)
The confusion matrix divides prediction in true positives (TP), true negatives (TN), false positives (FP), false negatives (FN). The second word refers to the result of the prediction and the first word says if this prediction was correct or not. \[Pr=\frac{TP}{TP+FP}\] \[Re=\frac{TP}{TP+FN}\]Is accuracy always a good metric?
(click to view answer)
No, it is not. If using a testing set with an uneven distribution e.g. N samples where N-1 samples are benign. A dumb classifier that always classifies samples as benign would achieve a accuracy of: \[\frac{N-1}{N}\]What are causes of concept drift?
(click to view answer)
Concept drift referring to dataset shift hereNon stationary domain, sampling selection bias.
Vulnerability #
Name different representations of code as a graph.
(click to view answer)
Control Flow Graph (CFG), Program Dependence Graph (PDG), Abstract Syntax Tree (AST)Rank the following (types of) words according to their expected TF-IDF. Explain the rationale behind TF-IDF.
- a word that is common in every document.
- a word that is not present in the current document, but in every other document.
- a word that only occurs in the current document.
(click to view answer)
A word that is common in every document has a rather low TF-IDF as TF is high but IDF is very low. A word that is not present in the current document, but in every other document has a zero TF-IDF as TF is zero. A word that only occurs in the current document has a high TF-IDF because TF at least not zero and IDF is maximal.
The rationale behind TF-IDF is to have a measure for discriminatory terms. This is done by assigning high values to terms that often occur in a document (i.e. being characteristic for this document) but do not frequently appear in other documents in a given set (i.e. discriminating a document from others).
Briefly explain the Heartbleed vulnerability.
(click to view answer)
I honestly doubt that this will be an exam question But in all brevity: It was a taint style vulnerability in OpenSSL where the length of the requested data was taken from the request itself and not checked. This allowed attackers to perform a buffer-over-read and possibly get private information such as encryption keys.Why do we apply dimensionality reduction?
(click to view answer)
We want to get rid of noise in the data while still retaining relevant data. Therefore we apply dimensionality reduction in the form of principal component analysis.What are the two approaches to vulnerability discovery mentioned in the lecture?
(click to view answer)
- Finding vulnerabilities referring to similar vulnerabilities.
- Identifying abnormal code patterns
How is code mapped to meaningful features? What do we need for this mapping?
(click to view answer)
Mapping with sub-trees/ sub-graphs: $$\phi(x) = (w_s * occ(s,x))_{s \in S}$$ Needed are a structural representation of the Code yielding S (e.g. ATS, CFGs, PDGs or CPGs) and weights which can be e.g. tf, idf or tfidf.)What is the idea behind taint-analysis? Is it a method of static or dynamic program analysis?
(click to view answer)
Taint analysis is trying to find relations between user input and input to security critical sinks. Taint analysis can be both static and dynamic analysis.Fuzzing #
Name different types of fuzzers depending on how the input is generated.
(click to view answer)
Generation-based, mutation-based and evolutionary-bases.Name different types of fuzzers depending on the level of awareness of the program structure. Compare the three fuzzer types based on their computation time.
(click to view answer)
White-box fuzzers, Grey-box fuzzers, Black-box fuzzers. For per run execution time White-box fuzzers are the slowest and Black-box fuzzers the fastest. Depending on the specific fuzzer and its implementation grey-box fuzzers can be almost as fast as black-box fuzzers. AFL for example approximates coverage with a bitmap and uses multiple threads and therefore achieves a large number of executions.AFL can be viewed as a genetic algorithm. What is its fitness function?
(click to view answer)
The number of newly covered edges of an input.What is NEUZZ? What is the rough idea behind it?
(click to view answer)
- NEUZZ (=Neural Programming Smoothing) view Fuzzing as an optimization problem where the number of found bugs (F(x)) for all used input x is maximised.
- It then abstracts (like others, too) from that specific goal and uses the edge coverage (=path coverage/ code coverage?) G(x) for the optimization.
- Lastly, it approximates G(x) with a differential, smooth function H(x) learned by a NN.
- On H(x) the gradient for a certain x can be computed and used to update x/ find the optimal set of input x to maximize H(x).
What is the/ are some main ideas of AFLfast?
(click to view answer)
The idea is to view the fuzzing process as a markov chain, that models the probability that fuzzing a seed which exercises a path i in the program generates a new input that exercises path j. To reach a good code coverage fast, there should be more time spend on low frequency paths (path with a low probability). To approximate this, energy schedules are introduced. They start with a low energy (# of fuzz generated from an input) of a path and then increase the power exponentially observing how much new edges are covered.Explainable ML #
How can descriptive accuracy be measured?
(click to view answer)
It is indirectly measured by removing the k most relevant features and observing the decay of the prediction function. We are expecting a rather sharp decay.Name three advantages of white-box explanations over black-box explanation tools.
(click to view answer)
They are faster, complete and deterministic.What is LIME?
(click to view answer)
A fruit and a black-box tool for explainable machine learning that extracts the k most relevant features from a given sample. This is done by approximating regions of a decision function with surrogate models.What are the two main approaches for black-box explanations? Name and explain them.
(click to view answer)
Local and global surrogate models. For global surrogate models we try to approximate the whole classifier function. For local models we divide the classifier into local regions and try to approximate those regions with separate surrogate models. For some small enough regions even linear models yield good results.Provide an example where using a global surrogate model might be problematic. How can we solve this?
(click to view answer)
If the decision function is very complex the chosen interpolation of the surrogate model may not provide a good enough approximation. If we can't find a fitting function for the surrogate model we can break the global model apart in to local regions where simple e.g. linear functions provide good results.Adversarial ML #
What is the difference between a sparse and a dense attack?
(click to view answer)
When coming up with adversarial examples that change an sample just so much that it is classification changes, we can either do a greedy search without any further constraints. This is called sparse attack. For an image for example we change a few pixels that have to most influence on the decision. Those samples may end up looking “unnatural”, so a human analyst may suspect adversarial machine learning when looking at such a sample. Therefore we also can do dense attacks, where we distribute the change over the all values, constraining the change to an individual influential value. For images per pixel. In the resulting image the changes often are hardly visible and hard to distinguish from noise.Explain the challenges and constraints when coming up with adversarial examples in the field of malware code.
(click to view answer)
They must retain the malicious code in a reachable section. Related to this the code must be resistant to preprocessing e.g. dead code removal. Also the resulting code must look plausible. The added code should not be detected by common signature scans. Also ideally the removal or addition does not crash the program and maintains the original functionality.What methods of detecting adversarial examples and poisoning attacks are there?
(click to view answer)
Continuous testing and observation of the behaviour of a model. This can be done with different approaches.- Direct Testing
- Testing around the decision boundary
- Testing edge cases
- Observing neural coverage
- Differential testing
- Training multiple models and analyse differing classifications.
- Explainable Machine Learning
- For scenarios where we can monitor access to the classifier function and have some kind of access control in place. We can try to detect suspicious access pattern to the classifier and them block or timeout such accounts.
How does obfuscation of a prediction function work? Is it effective? Explain your answer.
(click to view answer)
We can make the model more complex to make it harder to figure out the exact decision boundary. And we can do random feature selection or add noise to the output. Those defences are ineffective, as surrogate models do an approximation so those methods are “averaged out”.What two basic types of strategies are used to defend against attacks on ML?
(click to view answer)
Integrated defense (creating learning functions that are attack-resilient) and operational defense (using classical security mechanism to protect a learning algorithm).What is security-aware testing?
(click to view answer)
Security aware testing aims to detect wrong and suspicious behaviour of classifiers in order to detect adversarial machine learning. There are different testing approaches.- Direct Testing
- Testing around the decision boundary
- Testing edge cases
- Observing neural coverage
- Differential testing
- Training multiple models (possibly even with different learning algorithms) and analyse differing classifications.
- Explainable Machine Learning
Name and explain different types of attacks against machine learning.
(click to view answer)
Poisoning attacks: Injecting a small set of samples in the training dataset in order to move the decision boundary. Attacks against Online Centroid Anomaly Detection: Here adversarial samples are given to an online system that does continuous learning in order to shift its notion of normality. Backdoor attacks: Injecting a small set of samples containing a trigger (for example a pixel pattern in an image) into the training dataset in the hope that the classifier now associates a trigger with a certain class C instead of the real features. Images with this trigger are now classified as class C in production. Model stealing: Try to steal a machine learning model by approximating it with a surrogate model. Model stealing is an attack in itself but also a tool for coming up with adversarial samples for the aforementioned attacks.What are useful general and security-related criteria to evaluate explanations?
(click to view answer)
- General
- Descriptive Sparsity
- Descriptive Accuracy
- Security related
- Efficiency
- Completeness
- Robustness
- Stability
You have successfully derived a surrogate model $\theta^+$. What attacks can you perform with it?
(click to view answer)
Besides the fact, that deriving a surrogate model can be considered an attack on its own (stealing IP), we can use the surrogate model to find candidates for adversarial examples with full access to the model and without to many possibly suspicious accesses to the real model. Also the surrogate model can serve as a starting point for model inversion attacks and membership and property inference.Why is there no strong security mechanism for ML to date?
(click to view answer)
Short answer, because nobody came up with one yet.Actually it is really hard to do for the general case, because the attacker is in control of the inputs. Even training data is often obtained from unknown sources and is super hard to verify and sanitize. Also the attacker can use (black-box) or even have insight into the function (white-box). Therefore all the security mechanisms are rather mitigations, that lead to an arms-race between attacker and defender.