- Wachter Space Blog about Security and Automated Methods/
- Posts/
- Operating System Security Lecture Summary/
Operating System Security Lecture Summary
Lecture summary of the lecture Operating System Security, organized with self test toggles. The lecture is concerned with binary exploitation from an offensive as well as a defensive point of view. I can really recommend the lecture, if you are interested in modern security mechanisms implemented by operating systems and hardware.
Basic Definitions
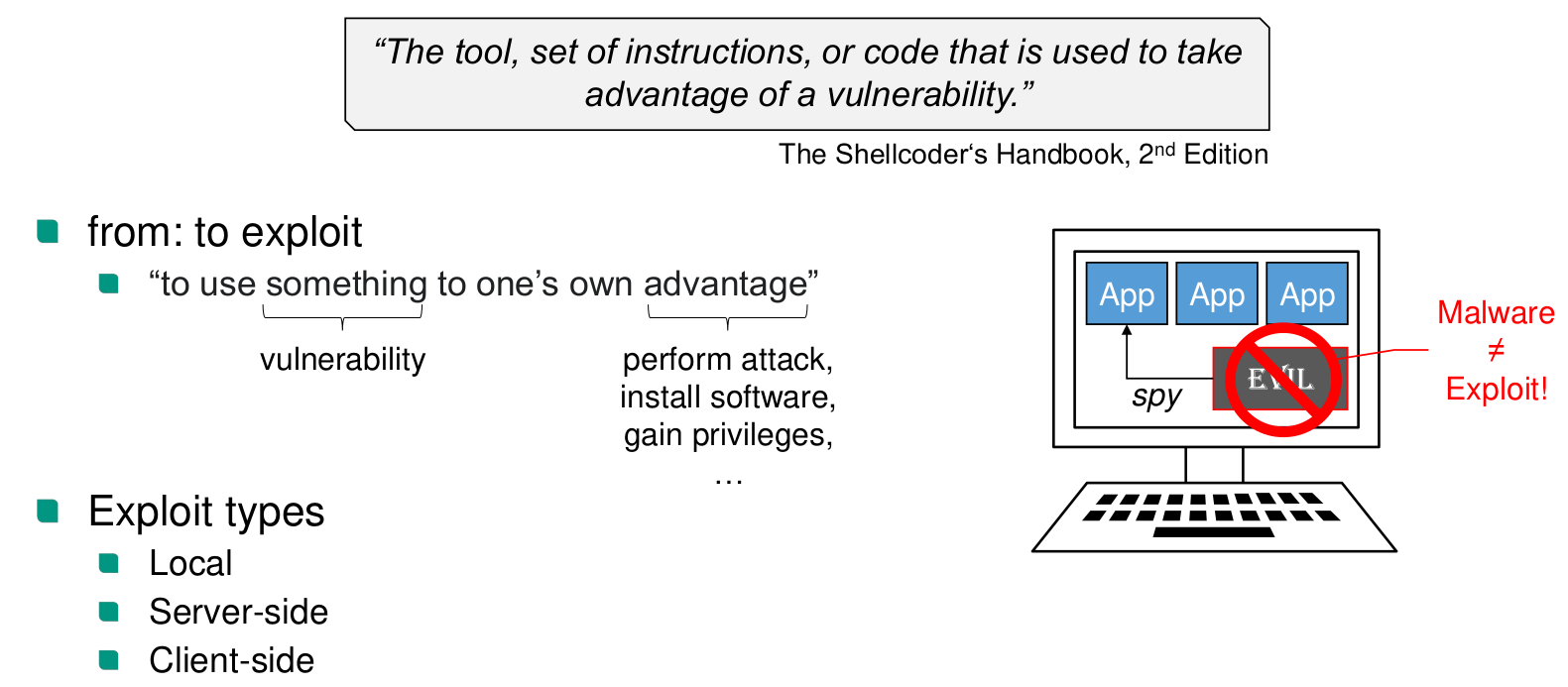
What is a vulnerability?

What is the definition of an exploit?
Set-uid-bit
Allows an executable, that is owned by the user, to use root privileges during execution
x86-64 execution environment
How to load the instruction pointer into
RAX?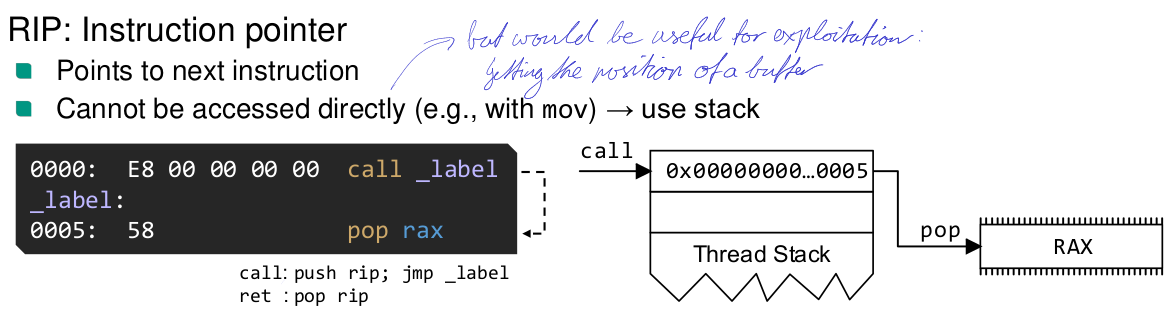

What does the
ret(C3) instruction do?A C3 is a short jump. It is equivalent to
pop rip
What does the
call(E8) instruction do?Near call of addr is equivalent to
push rip jmp addr
What is the value of
raxaftermov rax, 0x1122334455667788;mov eax, 0xffffffff;mov ax, 0xaaaa?
Calling Conventions
cdecl System V AMD64 Microsoft x64 Syscall ABIs
Stack Buffer Overflows
What can a stack buffer overflow be used for?
- Overwriting local variables
- ret 2 win
- ret 2 shellcode buffer
Remote exploits
What is a remote bind shell?
A remote bind shell opens a socket with a shell at a port on the victim machine. The problem is that firewalls might block exposing a port online
What is a remote reverse shell
The attacker opens a port on their system and lets the victim machine connect to it. Less likely to be blocked by a firewall, especially when using inconspicuous ports like 80
Windows Shellcode
Processes can’t interact with the NT Kernel directly, but need to call library functions in kernel32.dll and others, which in turn call ntdll.dll. The NT Kernel API is undocumented and changes frequently.
The position of dlls in address space is dynamic
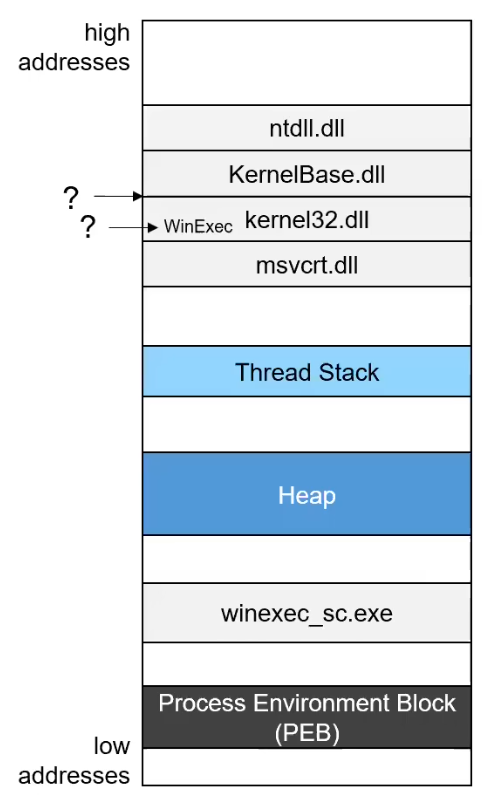
The PEB (Process Environment Block) contains useful addresses for finding out base addresses to the dlls. We can find the PEB via the TEB (Thread Environment Block). The TEB is always pointed to in by a segment register fs:0x30.
The offsets in the dll are dynamic. A dll is a PE file. A dll contains an export table. The export table contains relative virtual addresses. In the export table, there is an array of (function name, RVA) tuples.
What is a relative virtual address RVA?
An offset relative to the base, when the function is loaded into memory. It is not a file offset. RVA + base address = effective address
The standard for a POC exploit is WinExec("C:\Windows\System32\calc.exe", 1)
0-Free Shellcode
How can instruction detection systems detect shellcode?
- Unnatural use of bytes (not alphanumerical), no English words, bad grammar
- Signature for common decoders
- Dynamic execution
0-free Opcodes
- push/pop
mov eax, 0x1→push 0x1;pop eax
- xor to 0
mov eax, 0x1→xor eax,eax; inc eax
- assign to smaller parts of registers and if necessary use zero extension of 32-bit register variants
- Jump back to have negative offset instead of jumping forward
XOR Decoder
- straight forward
- just xor with key
- brute force key generation is fast enough
- decoder loops over payload and XORs it with key
AlphaNum Algorithm
Encode the two 4-bit nibbles of each input byte v with two alphanumeric bytes bx and by. So that it can be decoded using only XOR and IMUL operations
- Examine all the alphanumeric instructions
- Use
XORandIMULfor decoding
- Addresses and immediates are limited to alphanumeric range
- An extension for in-place decoding exists, with extra xor byte
Problem despite alphanumeric encoding: Return address is not alphanumeric.
English Shellcode
- Jump over bytes
- Use sandbox to test words and measure progress
Shikata Ga Nai (SGN)
- XOR key randomly changes
- The decoder itself changes randomly
- Changing instructions
- Changing order of instruction
- Junk instructions
- Changing used registers
- Can recursively encode itself
Exploit stability
- NOP Sled at start of buffer
Get buffer addresses from registers
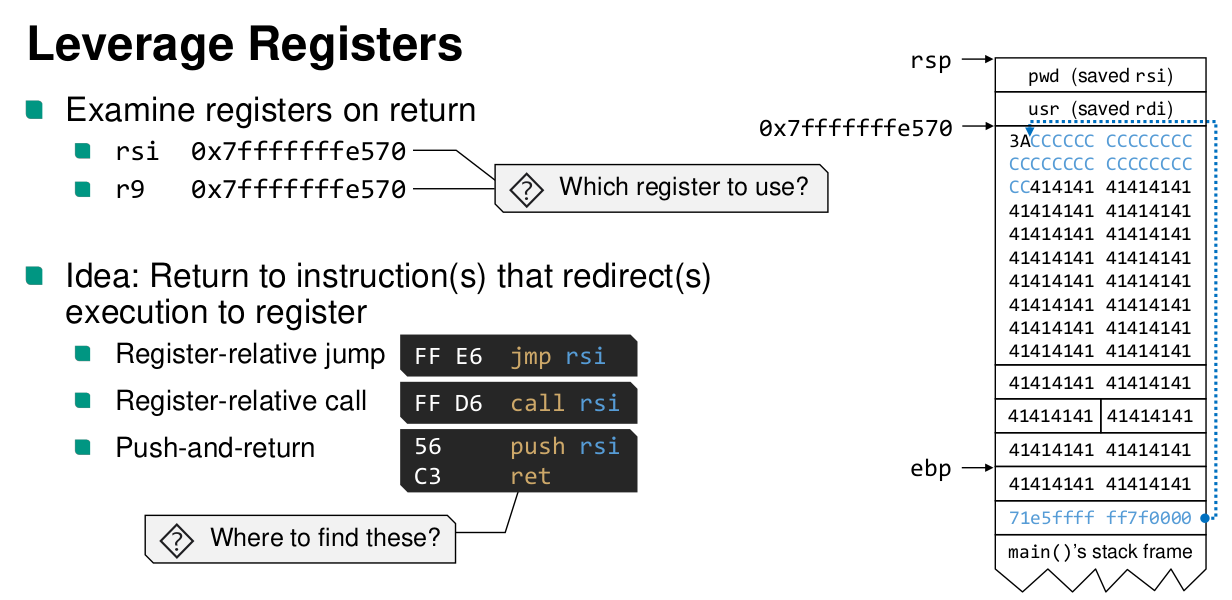
⇒ We have to know the address of this instructions, and not a stack address. Find gadget.
ROP
printfcan be helpful to prepare arguments
- There are ROP compilers
- ROP is often used to just mark the stack as executable
What is a
NOPinstruction in ROP code?The address to a single
ret
How can a string, e.g.,
"/bin/bash", be loaded?- Find string in program and gadget that loads address of it into register
- Place string on stack. Get stack address into register
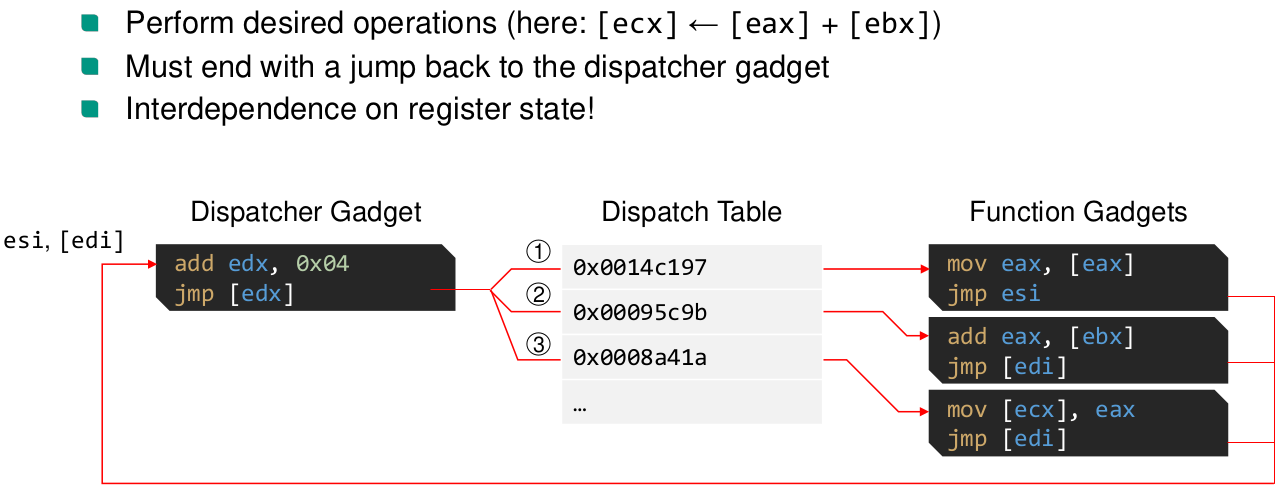
JOP
- not reliant on the stack for control flow
Dispatcher gadget

Dispatch table
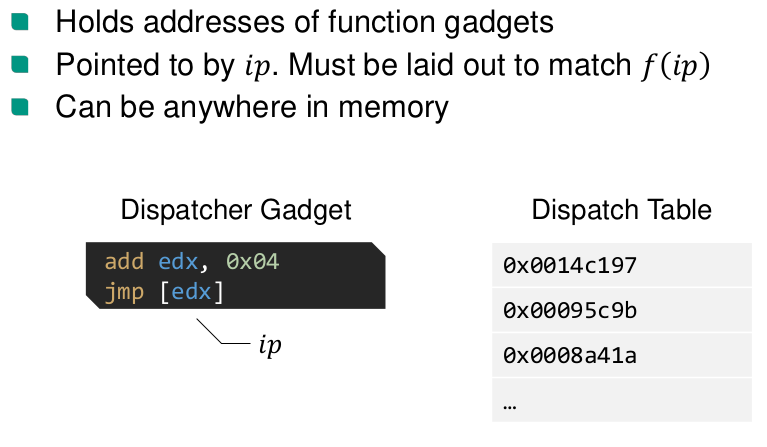
Function gadget
Mitigations
What is the mitigation against shellcode execution
Data Execution Prevention (DEP)
- Mark writable memory as non-executable (NX)
- W^X (write XOR eXecute)
How is DEP implemented?
- x86-64 added NX-bit in page table entry (hardware support)
How was it previously implemented?
- previously only on segment level (text segment not writable and data segment not executable)
- Can be emulated by the kernel, without hardware support, by marking non-executable pages as kernel pages
- Mark writable memory as non-executable (NX)
How can we prevent jumping to code in 32 bit code?
ASCII Armor
- For a 32-bit address space, place executable code at addresses with at least one 00-byte
- Prevents copy of ROP chain with
str*functions
- In a 64-bit address space, we always have 00-bytes at the beginning of the address for user space addresses.
How to bypass this mitigation?
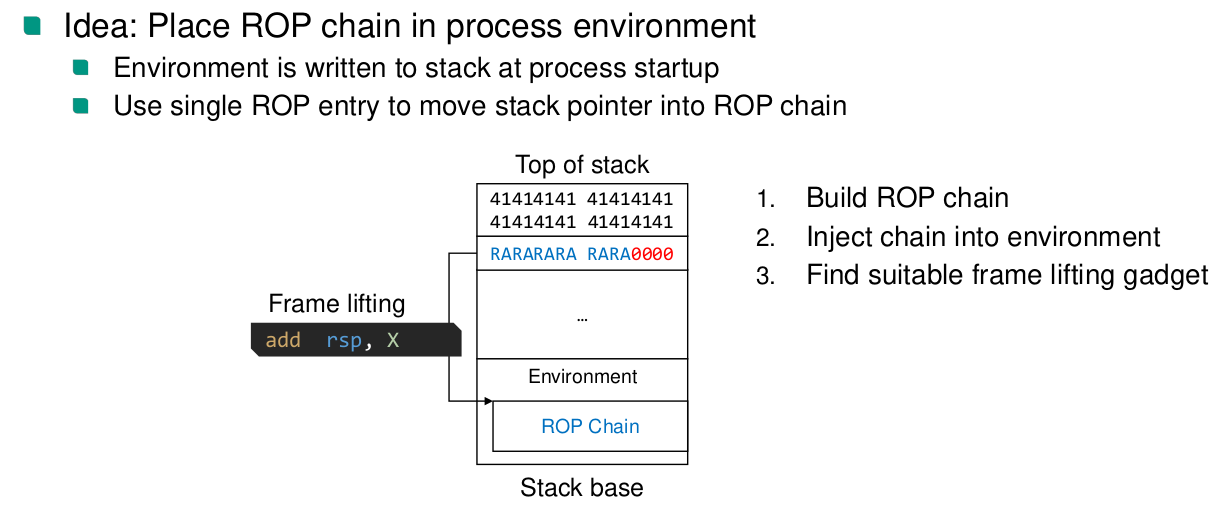
Null bytes can be generated with ending a string. Multiple null bytes with empty strings.
When redirecting the stack pointer to the environment, we need to be careful, so that the stack stays aligned
ASLR
How does dynamic linking work?
Dynamic Linking
Position independent code
- Relative addressing only
- External symbols accessed via GOT
Global Offset Table (GOT)
- Addresses of external symbols
- Created by static linker
- Initialized by dynamic linker at runtime
Procedure Linkage Table (PLT)
- Functions could also be in PLT, but with libraries a program typically only uses a few of the available functions
- Load libraries only when they are needed
- Load function addresses only when they are needed
External function call steps:
- Call PLT
call 401030 <puts@plt[1]>- PLT contains code
plt[0]: ; special plt entry. Calls dynamic linker push [rip+0x2fe2] jmp [rip+0xfe4] ; dynamic linker call ; Updates GOT entry with external function address. ; The dynamic linker also calls the function. ; Due to the ret the execution continues at the original call. nop ; never executed puts@plt[1]: jmp [rip+0x2fe2] ; GOT entry (initially points to address of init_plt) init_plt: push 0x0 ; index of GOT entry jmp plt[0]- On the next call, the GOT entry already contains the external function address.
- The code after init_plt will not be executed, because the function ends with return and will go back to the original call
What assumptions does ASLR depend on?
ASLR Randomness
When does randomization happen
- Only randomized at process start (
exec*)
- Not randomized at
fork- Allows attacks on worker processes: Guess an address, see if the worker crashes or new one is spawned or observe a desired response (e.g.
sleep)
- Allows attacks on worker processes: Guess an address, see if the worker crashes or new one is spawned or observe a desired response (e.g.
- Only randomized at process start (
Partial address overwrite
Big endian: low, not random, bits are first in memory
How much entropy does ASLR give us on 64 bit?

But not uniformly distributed!
High correlation between sections
Heap Spraying
Fill large parts of memory with big allocations: NOP sled + payload. Due to memory pressure on the heap, guessing an address has high chance of hitting the payload
ASLR Secrecy
Examples for ASLR Secrecy leaks
- Address leaks in crash logs with stack traces, debug messages, etc.
- Direct address leaks of the program, e.g. format string vulnerabilities
- Implementation issues

Explain the discussed Action Script vulnerability allowed defeating ASLR
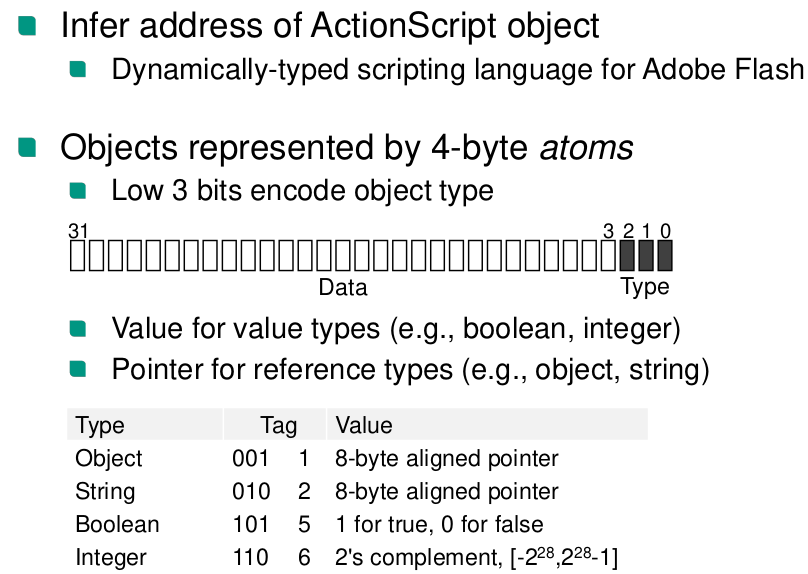
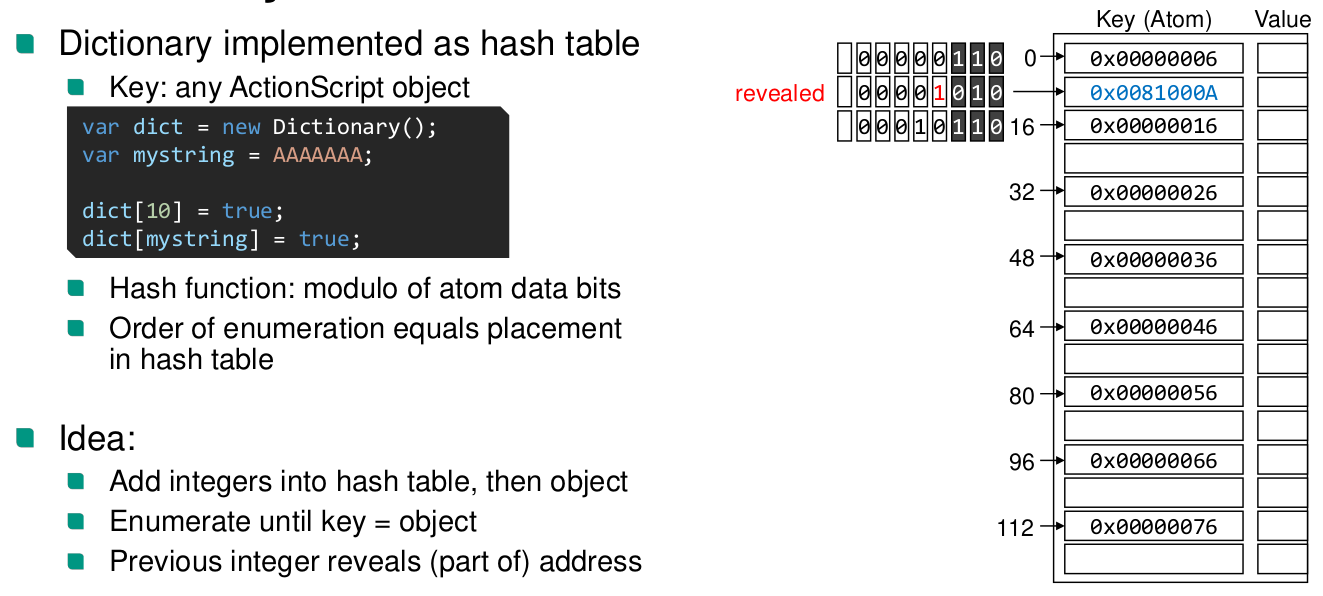
Fine-grained Re-randomization (research only)
What is fine-grained re-randomization?
Re-randomize the binary on crash/code probing
Problem: System-wide sharing of randomized binaries
Stack Canaries
Where is the stack canary stored?
Stack canary stored in thread descriptor (
glibc!tbchead_t), which is in the general purpose segmentfs.
How is the stack canary accessed?
- Stack canary is accessed via segment register
fs:0x28⇒ Can’t be accessed directly by user process
- Stack canary is accessed via segment register
- Put canary value on stack as before control area
- Before return, compare the value on the stack with stored canary
Different options for canary value
- terminator canary: Fixed value composed of string terminators
- Ineffective against non-str*-based overflows
- Random canary
- Ineffective against direct write into controllable area
- Random XOR canary
- Stack canary is XORed with control area
- Higher run-time overhead
- terminator canary: Fixed value composed of string terminators
What type of canary is used by the glibc
- The glibc canary is a random canary with a null byte at the end
What bypasses have we learned about?
- If read-primitive available
- Retrieve canary from current stack frame
- Retrieve reference canary
- Byte-by-byte attacks
- forked processes share canary value
- Don’t overwrite canary. With direct write primitive, just overwrite return address
- Overwrite pointer to reference canary in local function
- If read-primitive available
Stack Smashing Protection (SSP)
What is stack smashing protection?
- Copy arguments at top of stack frame
- Place buffers below other local variables
- Reordering does not happen for structs

Control Flow Integrity
Fine-grained control flow integrity
What does Fine-grained control flow integrity do?
Only allow valid edges in CFG. Each callee checks if caller is valid. Caller checks if return happened from callee.
What are problems of fine-grained control integrity?
- Generally undecidable
- Even if solution exists, high run-time overhead
Control flow guard (Windows)
- Verifies address is any legitimate indirect jump target (coarse-grained CFI)
- 16 byte alignment of functions
- Check the rest in a bitmap
How does the bitmap work

Where and how is the bitmap stored

How are statically imported functions handled

How are dynamically imported functions handled


Possible CFG attacks

Can be further mitigated by strict CFG, which does not allow non-CFG modules
Arbitrary Code Guard (ACG)
The program can specify a point after which there can’t be any dangerous calls anymore. Kind of a seccomp for CFG critical functions.
Back to epilogue
https://www.ndss-symposium.org/wp-content/uploads/2018/02/ndss2018_05A-3_Biondo_paper.pdf
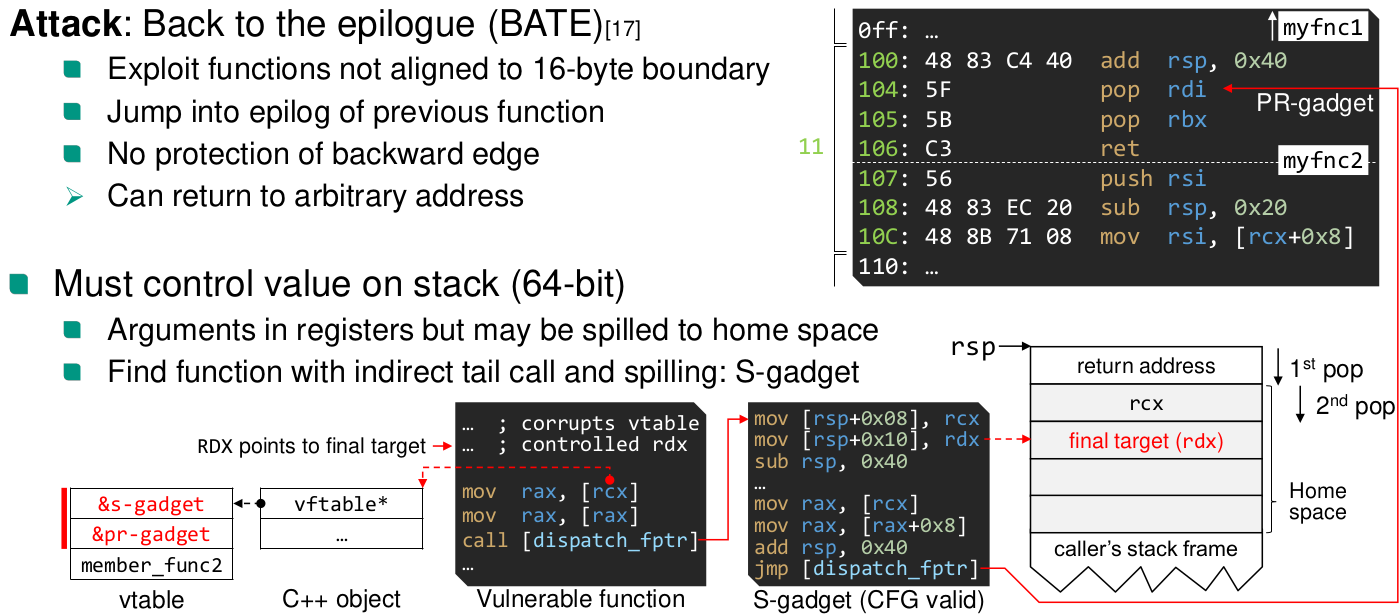
Hundreds of PR- and S-gadgets on modern Windows 10 Spread over important system and program DLLs (msvcrt.dll!) Applicability shown for (legacy) Edge browser
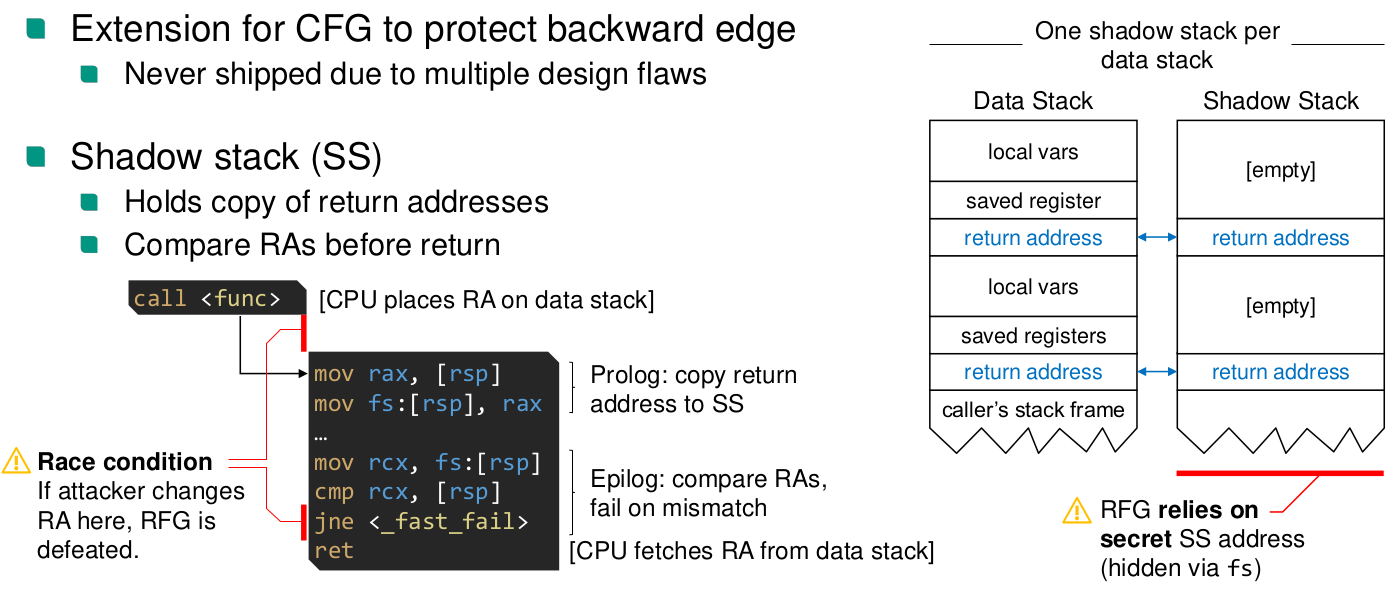
Return Flow Guard (Windows, not implemented because of flaws)
What is return flow guard?
- Make sure that return address can’t be tampered with
- Have a shadow stack that stores the return addresses and compare with return address on actual stack
RFG weaknesses
Control Flow Enforcement Technology (CET)
What is CET
- Hardware-enforced coarse-grained CFI
- Verifies address is any legitimate indirect jump target
- Joint development of Microsoft and Intel
- Hardware-enforced coarse-grained CFI
What features does CET have?
- Features:
- Indirect Branch Tracking (IBT), protects forward edge
- Hardware enforced shadow stack (SS), protects backward edge
- Features:
How is IBT implemented?
- Mark valid jump targets with new instruction: ENDBR{32/64} instruction
- ENDBR must be executed after indirect call
- Interpreted as NOP on old CPUs
- Encoded as 2 byte instructions, where the parts are kernel instructions
- No-track prefix 0x3E can be set for call/jmp to exclude from ENDBR checking for near calls
- ENDBR is implemented with state machine in CPU

- separate state machines for kernel and user mode
- System call entries are marked with ENDBR. So the kernel state machine is always in wait on entry.
- For thread switches, the state machine is saved as part of the context
- Legacy code support with a bitmap of page granularity
- Linux does not implement legacy support
- Mark valid jump targets with new instruction: ENDBR{32/64} instruction
How is the SS implemented?
- Hardware Shadow Stack (SS)
- New internal register
- can’t be accessed directly. Only the following operations are possible
incssp regIncrement SSP by 4/8*reg[7:0]
rdsspregRead SSP into general-purpose register
wrssreg/[mem]Write content to shadow stack at SSP (Can be disabled)
wrussreg/[mem]Write content to user shadow stack at SSP (kernel instruction)
- Shadow stack pages are marked as read only, write can only happen to save return addresses. Implemented by setting the dirty and read only bit for page.
- Shadow stack switching
rstorssp [mem]andsaveprevsp
- Implemented via shadow stack tokens
- Hardware Shadow Stack (SS)
Integer Overflows
Categories
- Arithmetic overflow
- Signedness bugs
- Truncation

How to fix the above code?
void *calloc(size_t nmemb, size_t size)
Use After Free
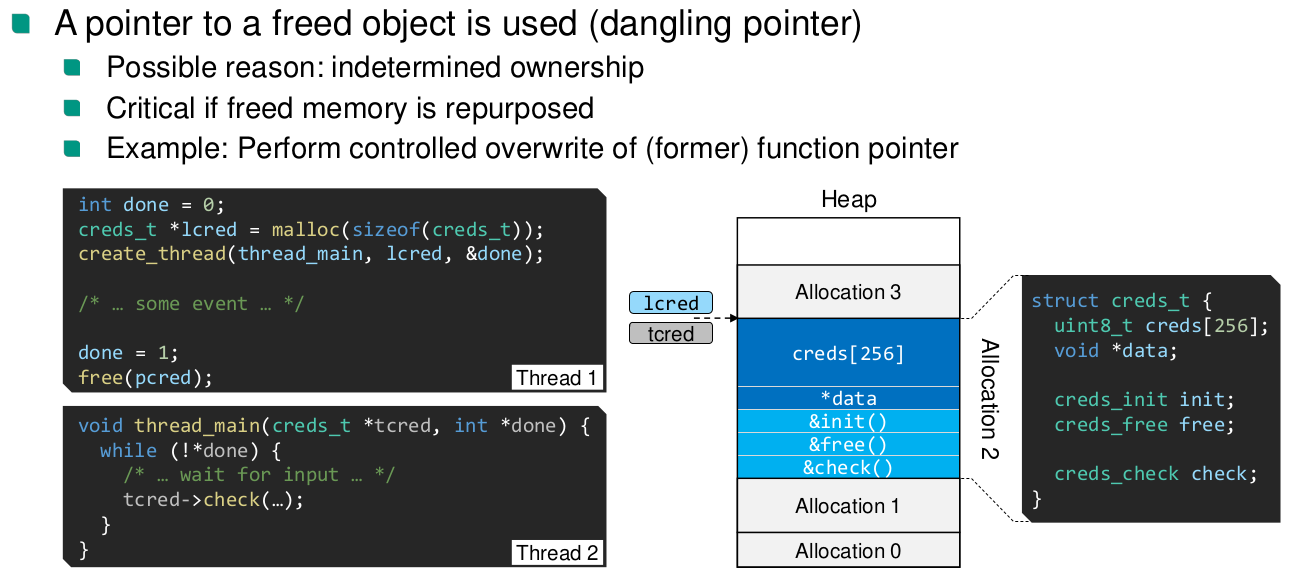
Type Confusion
In this example: Attacker controlled integer is interpreted as a function pointer
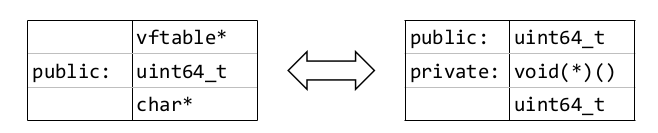
Time-Of-Check To Time-Of-Use
- Value is checked ✅
- Time passes, other threads/processes are able to change the value ⌛
- Value is used ⚡
Side Channel Attacks
What is the definition of a side channel attack
Infer secret data, by observing artifacts of execution across security domains.
Examples: Timing, cache, power-analysis, electromagnetic measurements
Meltdown
- CPU weakness allows reading any currently mapped page, including kernel pages
- Very fast reading speed: 5 KB/s - 500 KB/s
- Speculative execution of illegal branches leaves traces in microarchitectural state (e.g. caches)
- Pages that are accessed in illegal branch remain in cache.
- Accessing them is fast
How is the attack conducted?
- Construct an array of 256 pages in memory (probing array)
- Register a SIGSEGV handler. That ignores the
- Flush the probing array pages
- Use a byte in kernel memory as index into the array and make the access
- Go through all pages in the probing array and measure how long it takes for the page to load
- Surround page access with memory fence (
mfenceinstructions), to prevent reordering of time
- Surround page access with memory fence (
- The kernel byte value is the index to the page that took the least time to load
- (Because of 0-bias, the CPU assumes 0 as index for speculative execution, do multiple retries)
Kernel Page Table Isolation (KPTI)
- Mitigation for meltdown
- Have user page table and kernel page table
- Separate page global directories
- Switch by toggling 12th bit in CR3 register
- Only map kernel page that is required for entry into the kernel
- We can also use process-context identifier bits (PCID, 12 bits) to reduce overhead
What causes the performance overhead for
- Constant: Writes to CR3 register (incl. TLB flush) → +400 – 500 cycles per round trip
- Variable: Subsequent TLB misses → depends on access patterns and support for PCIDs
- Performance overhead because of TLB flush
Meltdown-P
- Also known as Foreshadow
- NG-OS
- Allows reading L1-cache contents
- Even if present bit is not set ⇒ L1 Terminal Fault

- NG-VMM
- VMs can access other VM via hyperthread
Spectre
Meltdown allows illegal access to memory that should be prevented by the architecture. E.g. kernel pages. Spectre allows access to data that should be prevented in software.
Spectre-PHT
Attack via the pattern history table.
How is the attack conducted?
- Train the branch predictor to predict with legal indices in
array1.
- Clear caches
- Then make an out-of-bounds access to an illegal address relative to
array1
- Analyze the access speed of
array2
#define PAGESIZE 4096 unsigned int array1_size = 16; uint8_t array1[16] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; uint8_t array2[256 * PAGESIZE]; uint8_t y; void victim_function(size_t x) { if (x < array1_size) { // Dieser Vergleich wird für die fehlerhafte Sprungvorhersage ausgenutzt y &= array2[array1[x] * PAGESIZE]; // Der Zugriff auf array2[] lädt eine Seite in den Cache, deren Adresse } // vom Inhalt von array1[x] abhängt. Das ist der verdeckte Kanal. }- Train the branch predictor to predict with legal indices in
Mitigations
- Do not offer precise timers
- Ineffective, because a precise timer can be constructed in many ways
- Isolate processes on other hyperthreads
- memory fences
- Throws away speculative execution speedup, if used too frequently
- No solution exists to detect critical points to insert (Microsoft tried and failed)
- Do not offer precise timers
Spectre-BTB
Branch predictors are shared between processes and also between user and kernel mode. One per hyperthread.
- The malicious process trains the branch predictor, so that it always jumps to a certain address, where the victim process has a gadget.
- Context switch to victim process happens
- For an indirect call, this address will be speculatively executed
- Gadget at address is an indirect memory access
- Allows attack process to infer the value, e.g., via cache analysis
Mitigation: Retpoline
- Mislead speculative execution for indirect calls
jmp raxis replaced with

call raxis replaced with
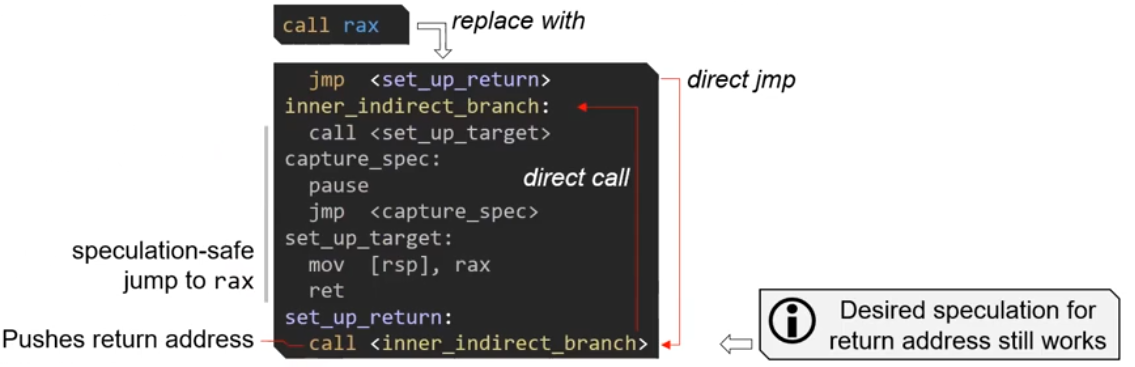
Software Side Channels
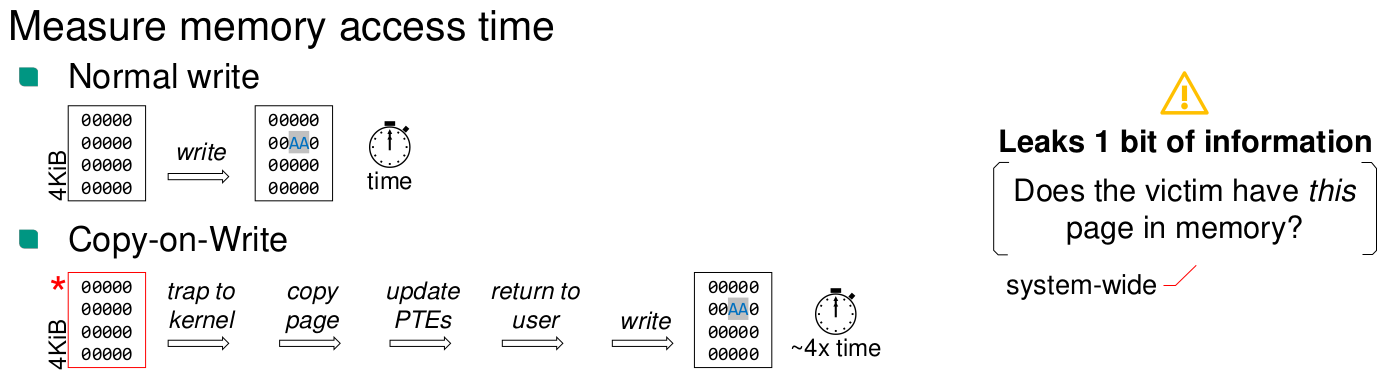
Memory Deduplication

Allows to leak if a page is used by another process
Rowhammer
Fast write to neighboring RAM rows to flip bits in other row
Covert Channels
Intentionally exfiltrate data across a security boundary that prohibits communication