- Wachter Space Blog about Security and Automated Methods/
- Posts/
- Privacy Enhancing Technologies Summary/
Privacy Enhancing Technologies Summary
Privacy
Definitions
Privacy dictionary definition
- the quality or state of being apart from company or observation : seclusion
- freedom from unauthorized intrusion <one's right to privacy>
⇒ right to be let alone
CS definition of privacy
the claim of individuals … to determine for themselves when, how, and what extent of information about them is communicated to others. ~ Alan Westin (1967)
Privacy Sphere model
Modelling protection requirements (expectations) of classes of information as concentric circles of decreasing need for protection.
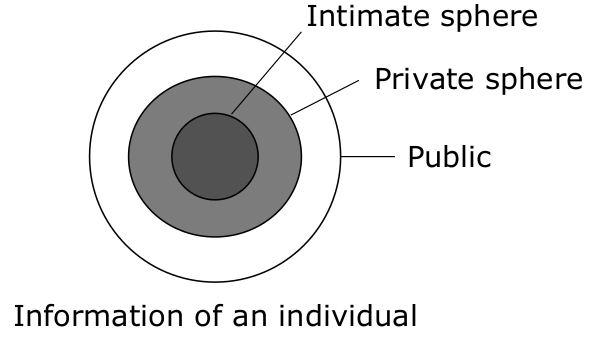
Cf. German constitutional court decisions about the absolute protection of the intimate sphere, that later got slightly diluted by the state trojan decision
Problems of the sphere model
- Assign data to corresponding spheres
- Assignment may depend on context and situation…
Privacy mosaic model. Is it good?
- Small snippets of information (probably) don’t expose a human
- Loss (and aggregation) of several snippets lead to a mosaic of the individual
- Increasing aggregation of puzzle pieces, increases detail of knowledge on the individual
- Management of pieces that initially are not considered “intimate” possible
- Independence of the way data is lost (or: collected)
- Does not simplify determining criticality of pieces
- Considers data capture/collection, but also further data processing
Privacy roles model
- Humans act in roles depending on their situation 🎭
- Usually specific information required to achieve certain task ✅
- Group shared information according to context 🔂
- Personas, various levels of sensitivity 🗝️
- Individual images to be restrained to context ⭕
- Transfer through 3rd parties may cause unknown leaks ❗
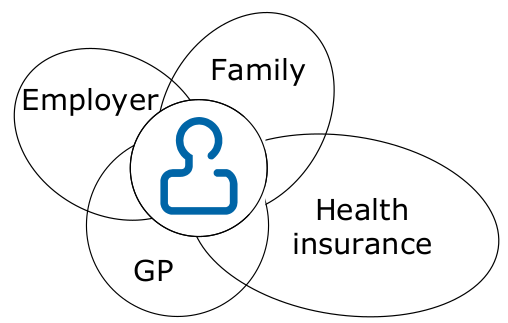
Consent Privacy Notion: Contextual Integrity
- Linked to the privacy as roles model
- Idea that data is shared with a specific mind set in specific context
⇒ expected privacy
Types of violation of expected privacy
violation of appropriateness of revelation
- the context “defines” if revealing a given information is appropriate
- violation: information disclosed in one context (even “public”) may not be appropriate in another (Asking a person participating in a gay pride vs. the same participating in a governmental press conference)
violation of distribution
- the context “defines” which information flows are appropriate
- violation: inappropriate information flows between spheres, or contexts; information disclosed in one context used in another (telling, even if first context was “public”)
Ethics in Research: Nuremberg code
Nuremberg code → Ethics in Research → Privacy (in Research)
- Required is the voluntary, well-informed, understanding consent of the human subject in a full legal capacity.
- The experiment should aim at positive results for society that cannot be procured in some other way.
- It should be based on previous knowledge (like, an expectation derived from animal experiments) that justifies the experiment.
- The experiment should be set up in a way that avoids unnecessary physical and mental suffering and injuries.
- It should not be conducted when there is any reason to believe that it implies a risk of death or disabling injury.
- The risks of the experiment should be in proportion to (that is, not exceed) the expected humanitarian benefits.
Definition informational self-determination
“The claim of individuals, groups and institutions to determine themselves, when, how and to what extent information about them is communicated to others” (GDPR: is processed)
Informational self-determination: Important underlying idea
European law (GDPR) is based on that idea:
The sovereign (self-determined) citizen controls collection, use, and can effectively retract even previously openly published data, upon change of mind
Difference: privacy and security
Privacy wants to minimize trust assumptions
- Security Model
- CIA
- Privacy Model
- Sphere
- Mosaic
- Roles
- Contextual Integrity
- Security Communication Model Attacker
- Eve
- Mallory
- Privacy Attacker
- Passive, Active
- Internal, External
- Global, Local
- …
- Security Model
Definition PETs
are coherent measures that protect privacy by
- eliminating or reducing personal data or
- by preventing unnecessary/undesired processing personal data
- without losing the functionality of the system
Data Protection
Principles of data processing according to GDPR
- collect and process personal data fairly and lawfully ⚖️
- purpose binding ➰
- keep it only for one or more specified, explicit and lawful purposes
- use and disclose it only in ways compatible with these purposes
- data minimization 🤏
- adequate, relevant and not excessive wrt. the purpose
- retained no longer than necessary
- transparency 🪟
- inform who collects which data for which purposes
- inform how the data is processed, stored, forwarded etc.
- user rights ✊
- access to data
- correction
- deletion
- keep the data safe and secure 🔒
How is personally identifiable information defined according to the GDPR
“personal data” shall mean any information relating to an identified or identifiable natural person (‘Data Subject’);
Difference between US law and EU law wtr. personal data
US: Name, address (Phone, Email), national identifiers (tax, passports), IP address, driving (vehicle registration, driver's license), biometrics (face, fingerprints), credit card numbers, date/place of birth (age, login name(s), gender, "race", grades, salary, criminal records)
EU: 'personal data' means any information relating to an identified or identifiable natural person ('data subject'); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person; [Art. 4, GDPR]
Are pseudonyms personal identifiable data
EU: 'personal data' means any information relating to an identified or identifiable natural person ('data subject'); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person; [Art. 4, GDPR]
Pseudonymous data can be linked back to individual, and it hence is considered PII!
Definition of pseudonym according to GDPR
A pseudonym is any unique piece of information corresponding to an identity (quasi id)
Types of data
- Data without any relation to individuals
- Simulation data
- Measurements from experiments
- Data with relation to individuals
- Types
- Content
- Metadata
- Revelation
- Consciously
- Unconsciously
- Types
- Data without any relation to individuals
Sources for data with relation to individuals
- Explicit
- Created content
- Comments
- Structural interaction (contacts, likes)
- Metadata
- Session artifacts (time of actions)
- interest (retrieved profiles; membership in groups/participation in discussions)
- influence
- Clickstreams, ad preferences
- communication (end points, type, intensity, frequency, extent)
- location (IP; shared; gps coordinates)
- Inferred
- Preference
- Image recognition models
- Personal details
- Externally correlated
- Observation in ad networks
- Explicit
Types of disclosures
- Disclosure of identity
- Identify an individual (in a dataset)
- Link identity to an observation
- Disclosure of attributes
- Infer a (hidden) attribute of an individual
- Link additional information to identity
- Disclosure of identity
Soft vs. Hard Privacy Technologies (with examples)
- Soft: Fully trust another party, to keep data private in the user's interest
- TLS
- Privacy settings on a web platform
- Hard: Semi-trusted participants, the goal is to reduce trust to a minimum and have mathematical privacy guarantees
- Soft: Fully trust another party, to keep data private in the user's interest
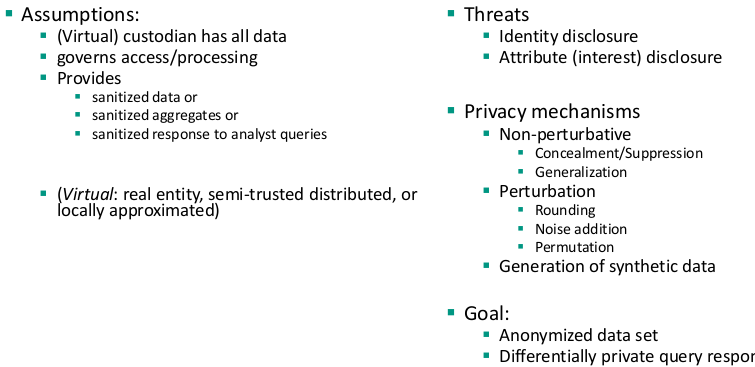
Statistical Disclosure Control
The (virtual) Curator
Lecture 3: Privacy Notions in Anonymous Communication
Definition Anonymity
Anonymity: “Anonymity of a subject means that the subject is not identifiable within a set of subjects, the anonymity set.”
IND-CPA
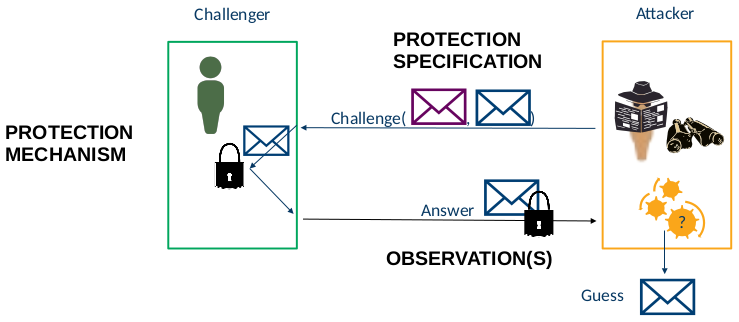
Communications

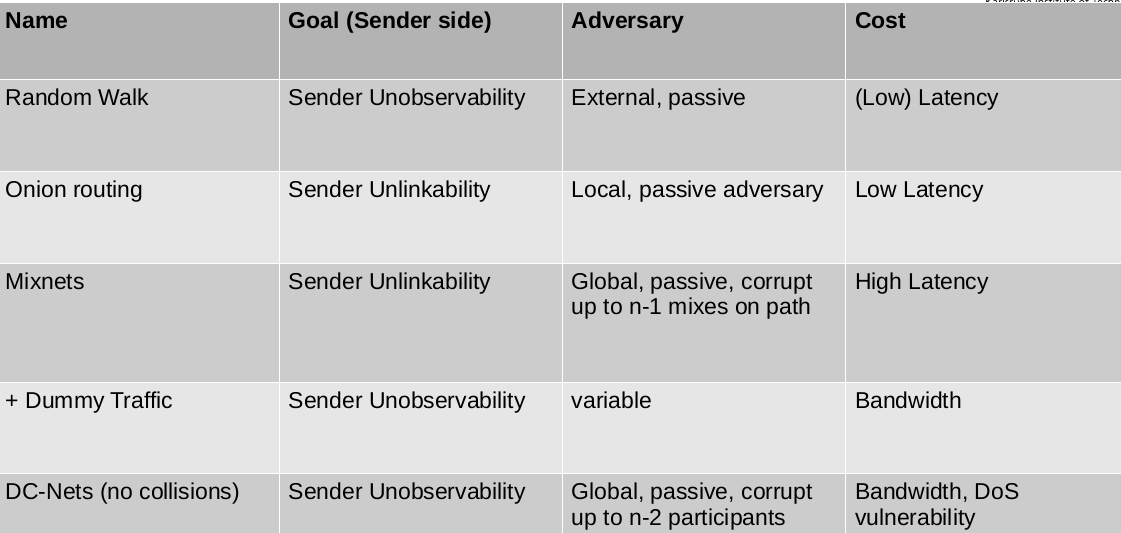
Sender Unobservability
we do not learn who sends something

Sender-Message Unlinkability
we do not learn who send which message (same receiver)
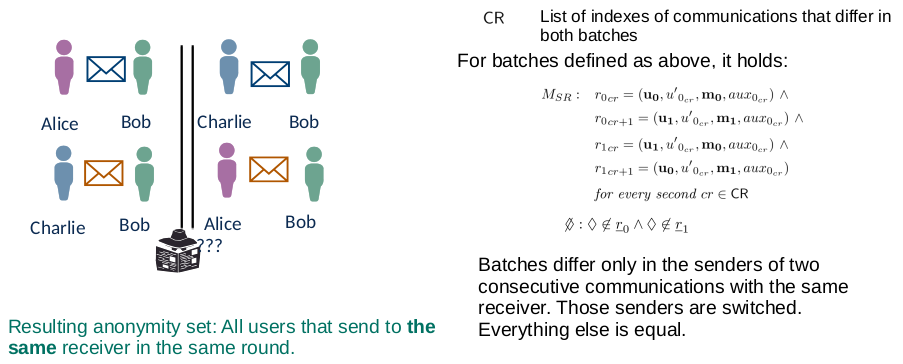
Sender Unlinkability
we do not learn who sends to whom (same message)
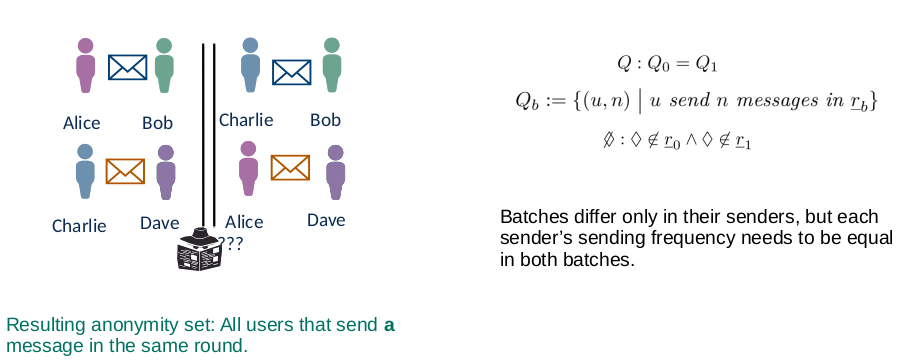
Sender-Receiver Unlinkability
we do not learn who sends which message or to whom

Hierarchy of ACN grantees
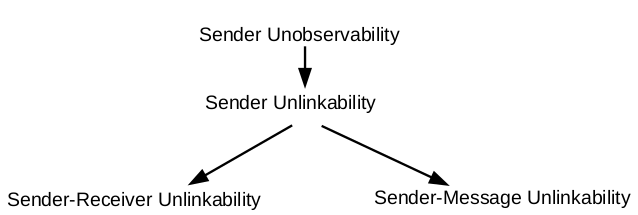
Is Sender-Message Unlinkability stronger than Sender Unobservability?

Is Sender Unobservability stronger than Sender Unlinkability?

Is Sender-Receiver Unlinkability stronger than Sender-Message Unlinkability?

How does Crowds work?
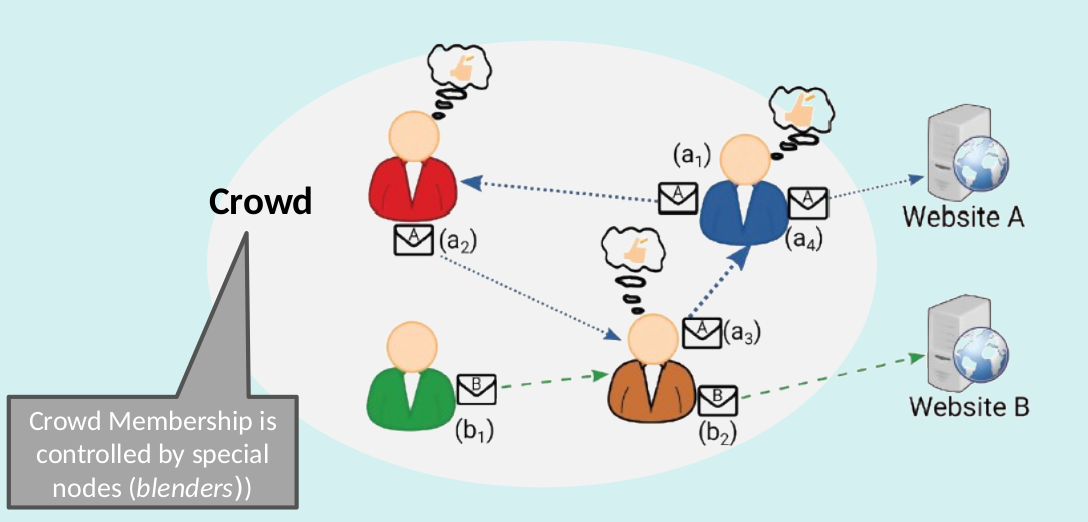
Crowds privacy guarantees
- Sender Unobservability
- Passive external receiver
- Higher latency Management overhead
- Availability risk (blenders)
Chaum’s Mix: Mix Cascade
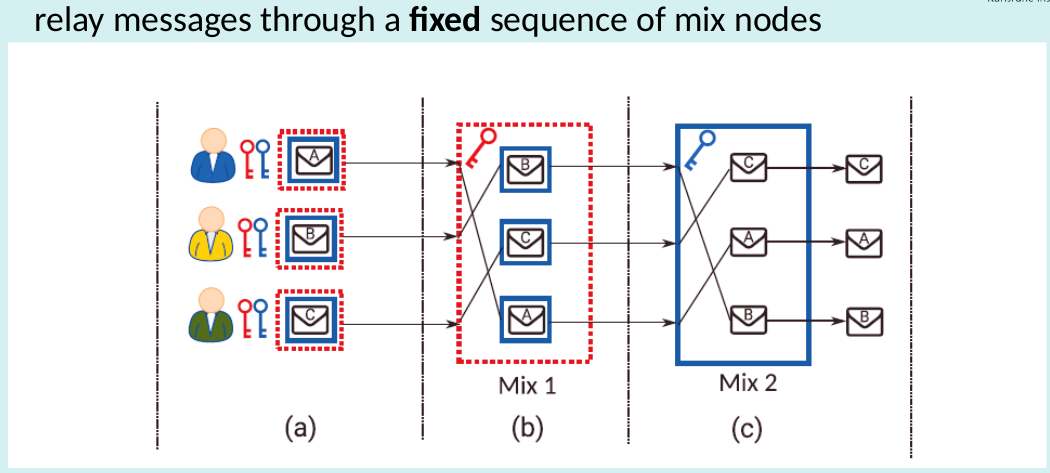

Chaum’s Mix drawback
- Availability drawback: Cascades = single point of failure
- Improve Availability: Free-route mix networks
- route is not fixed, any sequence of nodes from the network can be used for relaying messages
Mix Systems: mixing strategies

DC-Nets
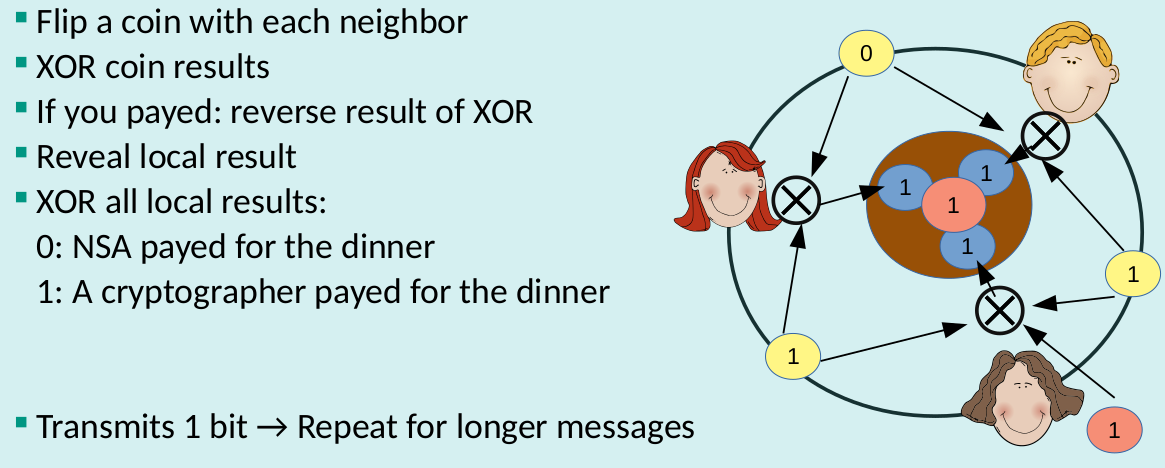
Properties of DC-Nets
- Sender Unobservability
- Global passive adversary and up to n-2 corrupt participants
- High bandwidth overhead Collisions and DoS Scalability issues
Protocol classes: Name, Goal, Adversary, Cost
Lecture 4: Privacy Metrics
Common components of privacy metrics
Adversary goals
- Goals include
- identifying a user
- user properties (interests, preferences, location, etc.)
- Metrics are defined for a specific adversary
- Goals include
Adversary capabilities
- Attacker’s success depends on its capabilities
- Metrics can only be employed to compare two PETs if they rely on the same adversary capabilities
- Taxonomy
- Local-global
- Passive-active
- Internal-External
- Prior knowledge
- Resources
- Data sources
- Published data
- Observable data
- Repurposed data
- All other data
- Input of metric
- Prior knowledge of the adversary
- Adversary’s resources
- Adversary’s estimate
- Ground truth/true outcome
- Parameters
Output measures
Uncertainty-based privacy metrics
- Assume that low uncertainty in the adversary’s estimate correlates with low privacy
- The majority of these privacy metrics rely upon information-theoretic quantities (e.g., entropy)
- Origin in anonymous-communication systems
- Examples
Anonymity set (size)
- Given a target member 𝑢, it is defined as the (size of the) set of members the adversary cannot distinguish from 𝑢
- The larger the anonymity set, the more anonymity a member is enjoying
- Widely used metric, not only in ACSs
- Simplicity, tractability are positive properties of this metric
- However: it only depends on the number of members in the system
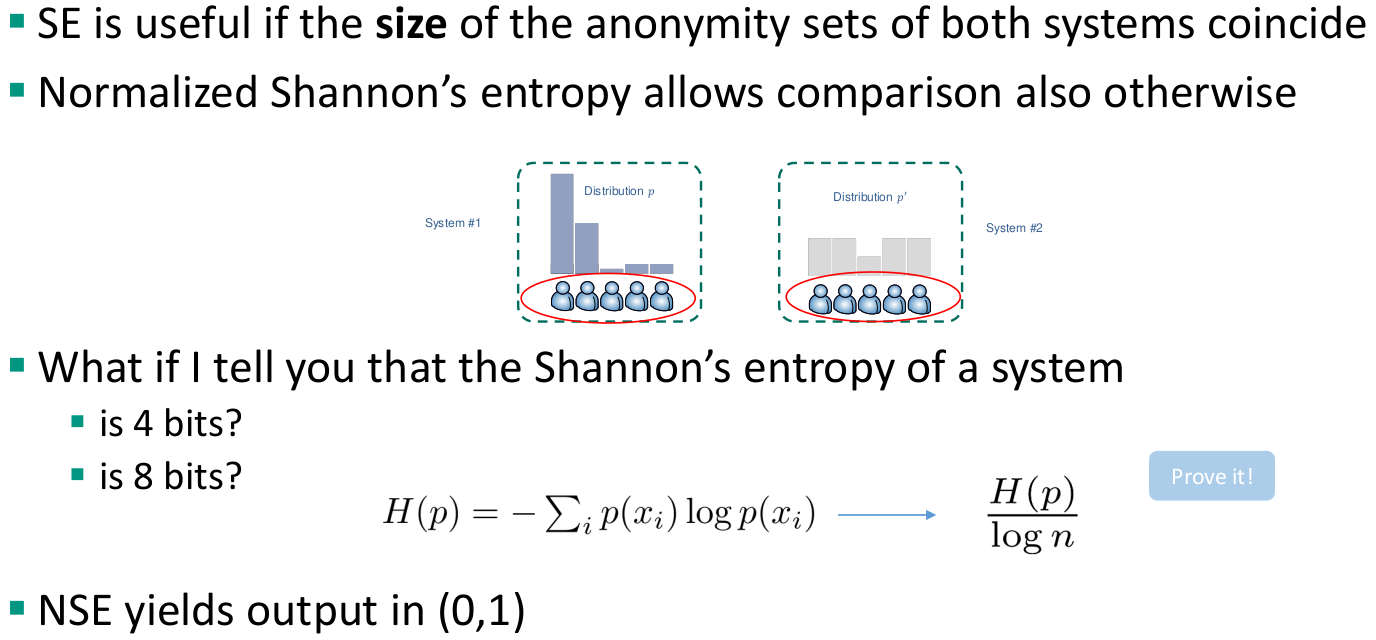
Shannon Entropy

Normalized Shannon’s entropy
Rényi’s entropy

Interpretation of entropy measures

Cross-Entropy

Information gain/loss-based privacy metrics
- Measure how much information is gained by an adversary after the attack
- Originate from information theory
- Applied to a variety of information, although mostly in anonymous Communications and database
- Well-known examples include
Relative entropy

Interpretation of relative entropy
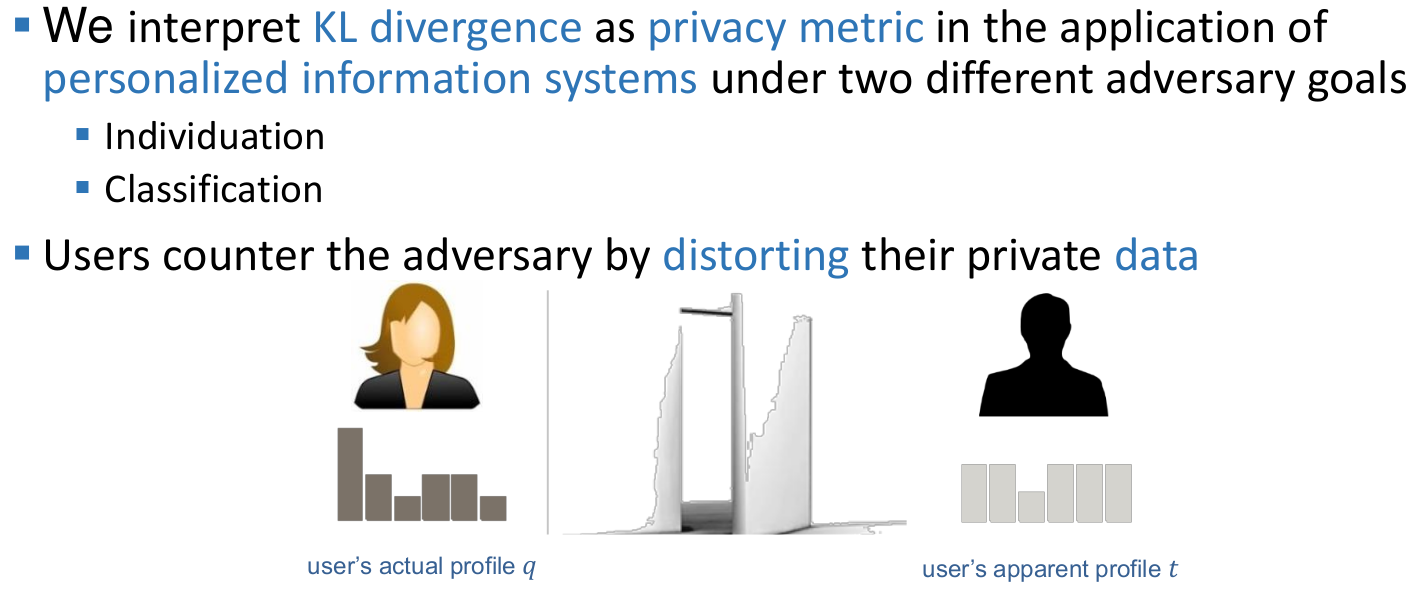
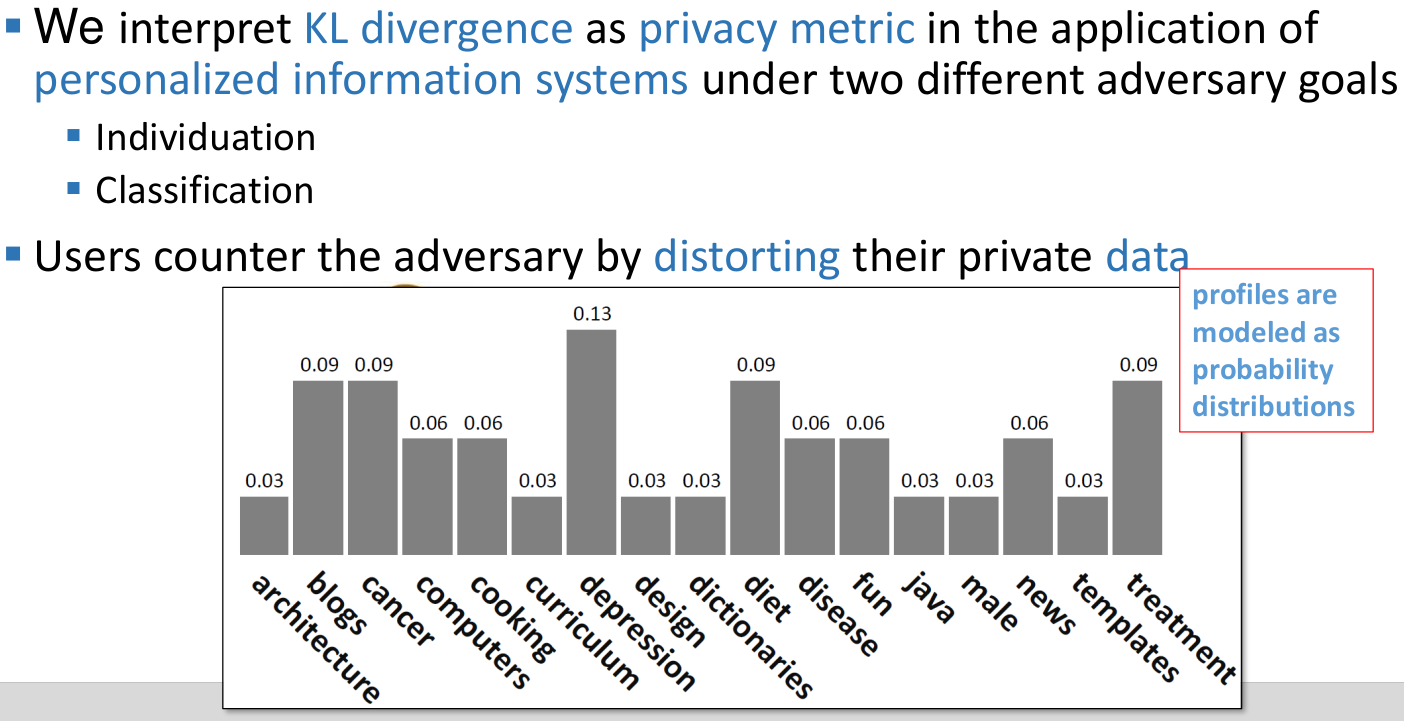
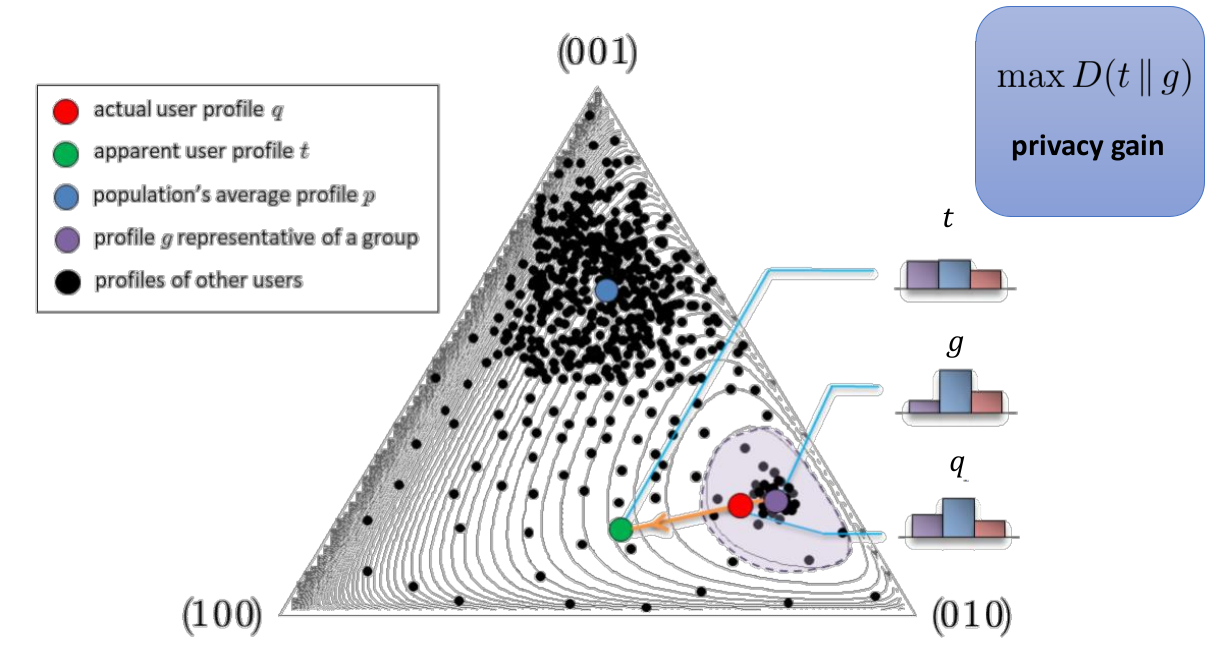
Mutual information

- Loss of anonymity
- Information privacy assessment metric (IPAM)
Data-similarity-based privacy metrics
- Arise in the context of database anonymity
- Measure properties of observable or published data
- Derive the privacy level based on the features of disclosed data
- Well-known examples include
𝑘-Anonymity
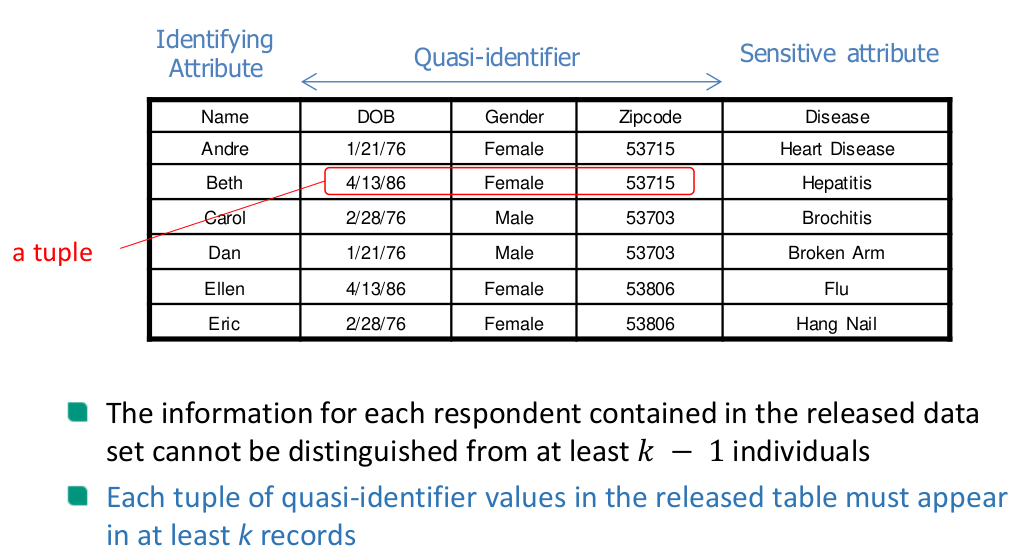
Limitations of 𝑘-anonymity
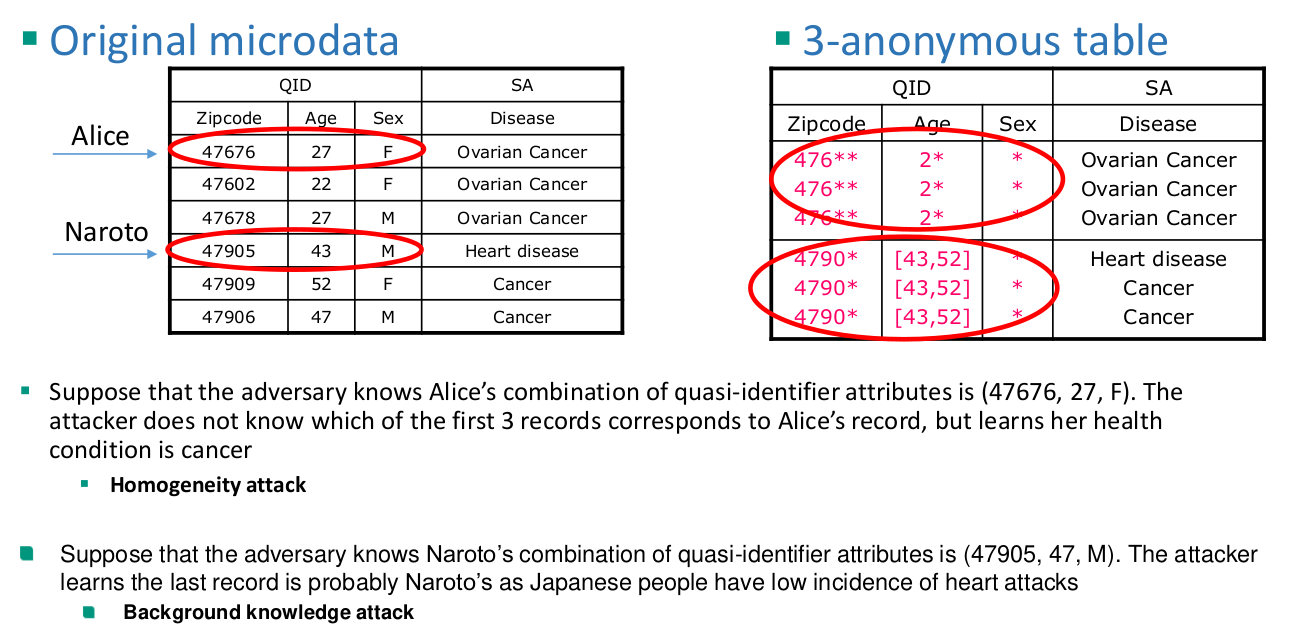
𝑝-Sensitive, 𝑘-anonymity
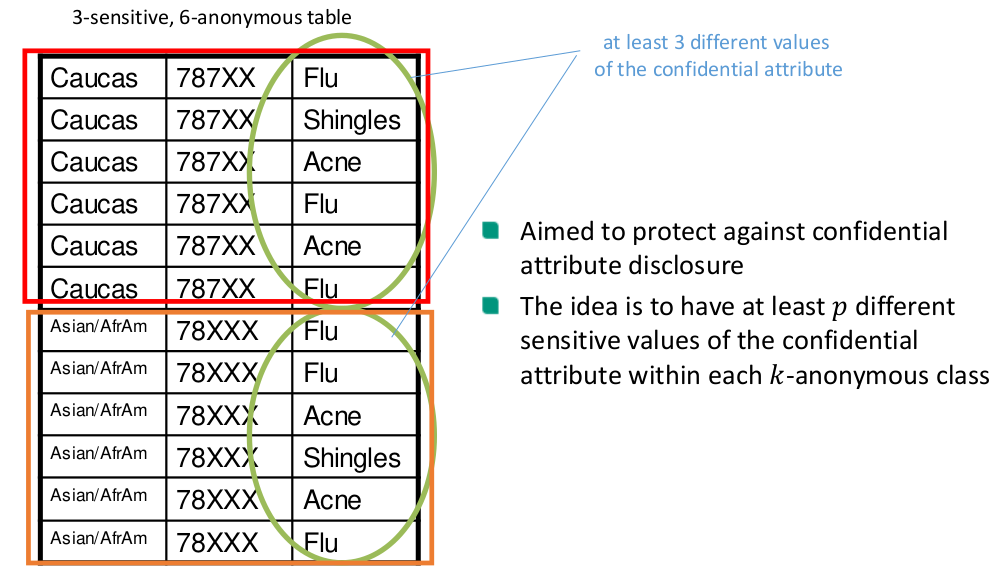
Limitations of 𝑝-sensitive, 𝑘-anonymity
Skewness Attack: If the relative frequency of a value within a cluster differs wildly from the overall one, a possibly more sensitive value can be strongly predicted for a target.
𝑙-Diversity

Limitations of 𝑙-diversity

𝒕-Closeness
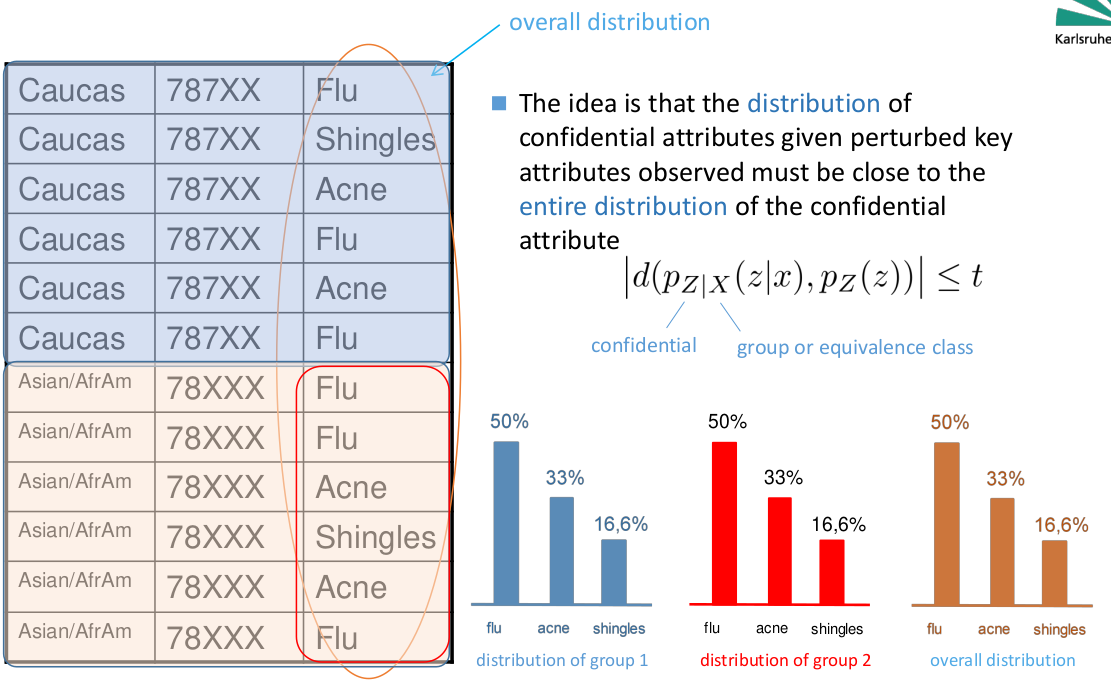
- stochastic 𝑡-closeness
Metrics based on adversary’s success probability
- Capture how likely the adversary will be to compromise our privacy in one or several attacks
- High privacy correlates with low success probability
- Examples include
Degree of anonymity

- Sender anonymity
Indistinguishability-based privacy metrics
- Is the adversary able to distinguish between two outcomes of a PET?
- The harder for the adversary to distinguish any pair of outcomes, the higher the privacy provided by the PET
- Typically binary metrics
- Examples include
- Differential privacy
- Individual differential privacy
Error-based privacy metrics
- Measure the error an adversary may make in their attempt to estimate unknown private information
- Examples include
- Correctness, by Shokri et al
Mean Squared error
Most popular measure of utility
Attacker’s estimation error
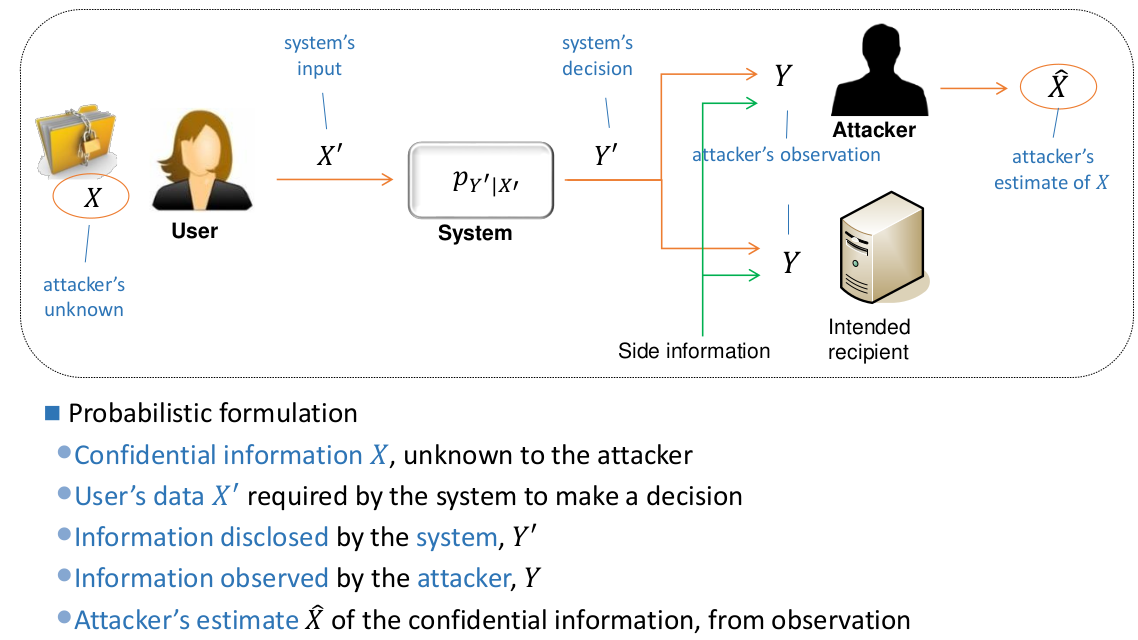

Time-based privacy metrics
- The output is time, an important resource for adversaries to compromise user privacy
- Pessimistically assume the adversary will succeed at some point
- Time until adversary’s success
- Define “success”: Able to identify 𝑛 out of 𝑁 of the target’s possible communication peers
- Maximum tracking time
- Privacy defined as the cumulative time the attacker tracks a user
- Assumes tracking is carried out only if the size of the anonymity set is 1
- Optimistic privacy metric
- Time until adversary’s success
The Inference Privacy Fallacy
- We measure the privacy of the data release mechanism
- We cannot protect adaptation of the prior (and corresponding inference)
- General: If statistics are revealed, they are useless or help improve the prior
Queryable databases protections
Query perturbation
- Deterministically correct answers not needed
- Input vs output perturbation
Query restriction
- Deterministically correct answers and exact are needed
- Refuse to answer to sensitivity queries
Camouflage
- Deterministically correct answers but non-exact are okay
- Small interval answers of each confidential value
Methods for microdata protection
Masking methods: generate a modified version of the original data
Perturbative: modify data
Microaggregation: Mask by grouping and replacement by “mean” value
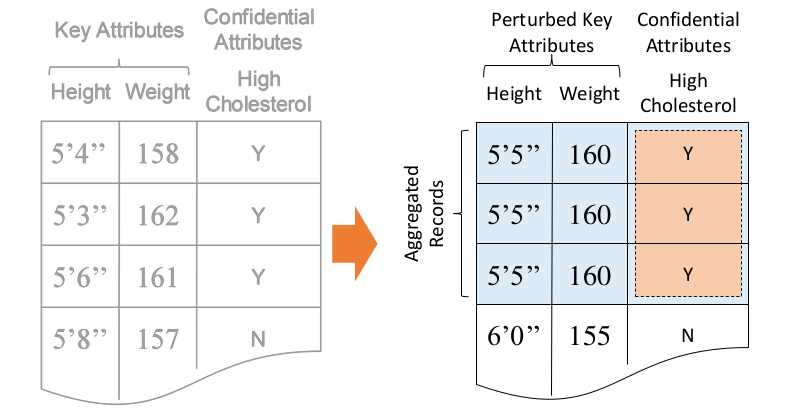
Microaggregation: SSE

Data swapping

Noise addition
- Uncorrelated noise addition
- Neither variances nor correlations are preserved
- Correlated noise addition
- Means and correlations can be preserved
- Noise addition and linear transformation
- Noise addition and non-linear transformation
- Uncorrelated noise addition
Differential privacy for microdata

Non-Perturbative: do not modify the data, but rather produce partial suppressions or reductions of detail in the original dataset
Sampling
- Publish random sample of the original set of records
- Correlation determines which properties are retained (uncorrelated: none)
- Continuous numerical data need further protection
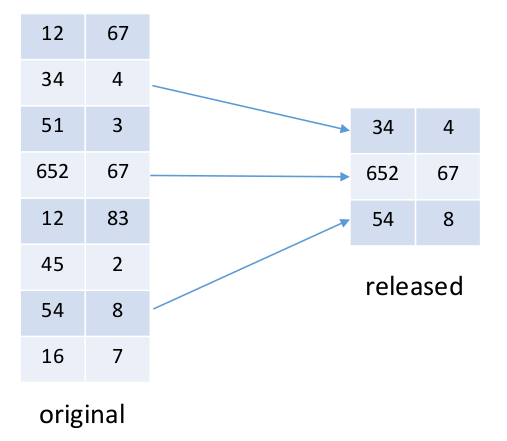
Generalization/Coarsening

Global recoding

Local suppression

Synthetic methods: generate synthetic or artificial data with similar statistical properties
- Extract chosen, preserved statistics from microdata (probabilities,distributions, ML models)
- Randomly generate data (sampling, transformation)
- Pros:
- Possibility to generate “unlimited” data sets
- seem to address the reidentification problem, as data are “synthetic”
- Cons:
- Published synthetic records can match an individual’s data, if model is not private
- Data utility limited to the statistics captured by the model
Differential Privacy
-Differential privacy

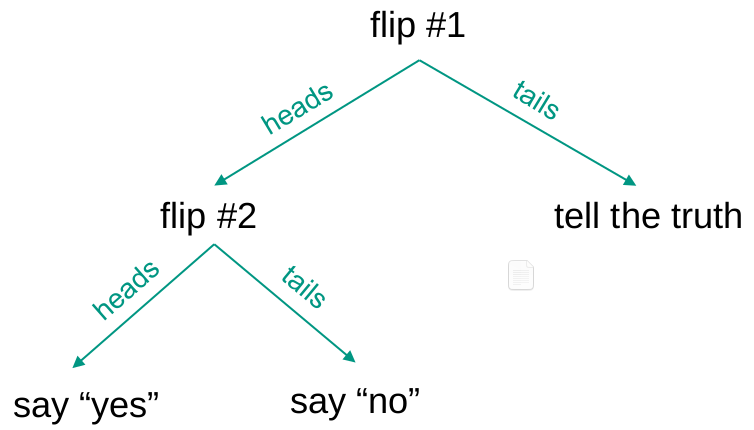
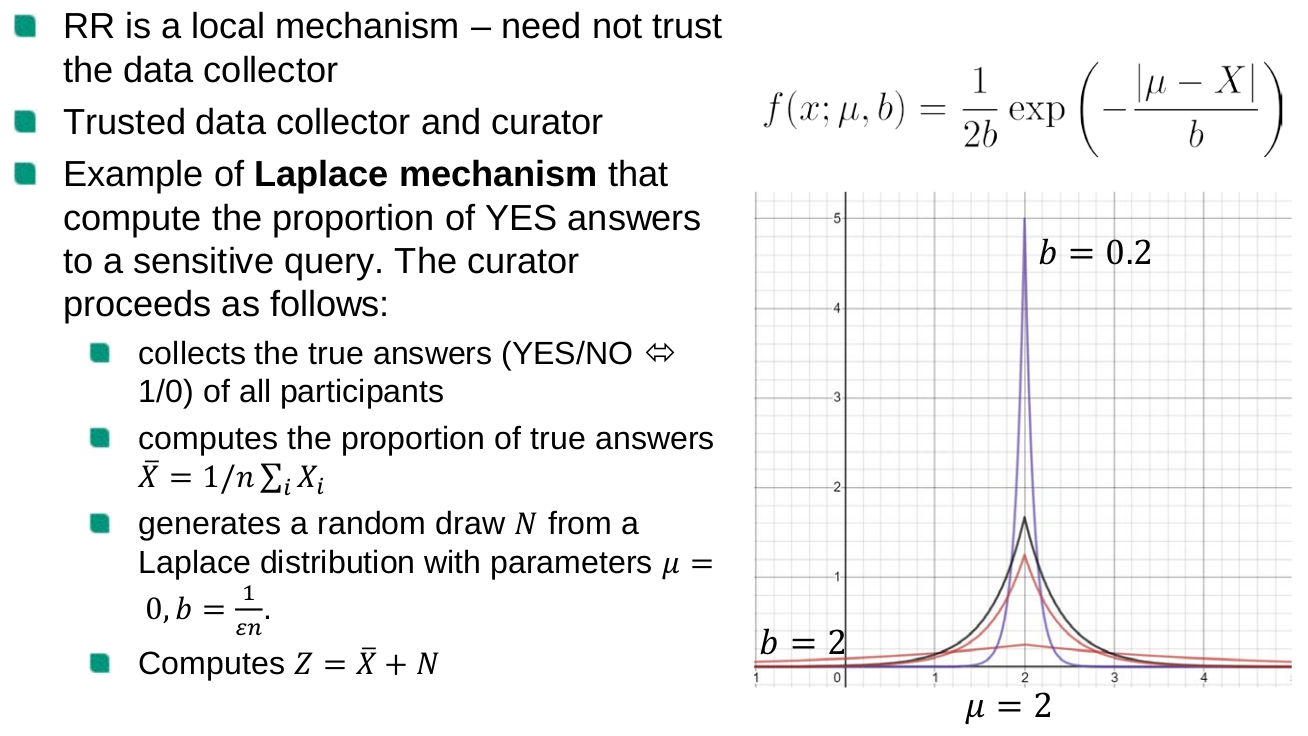
Randomized response protocol
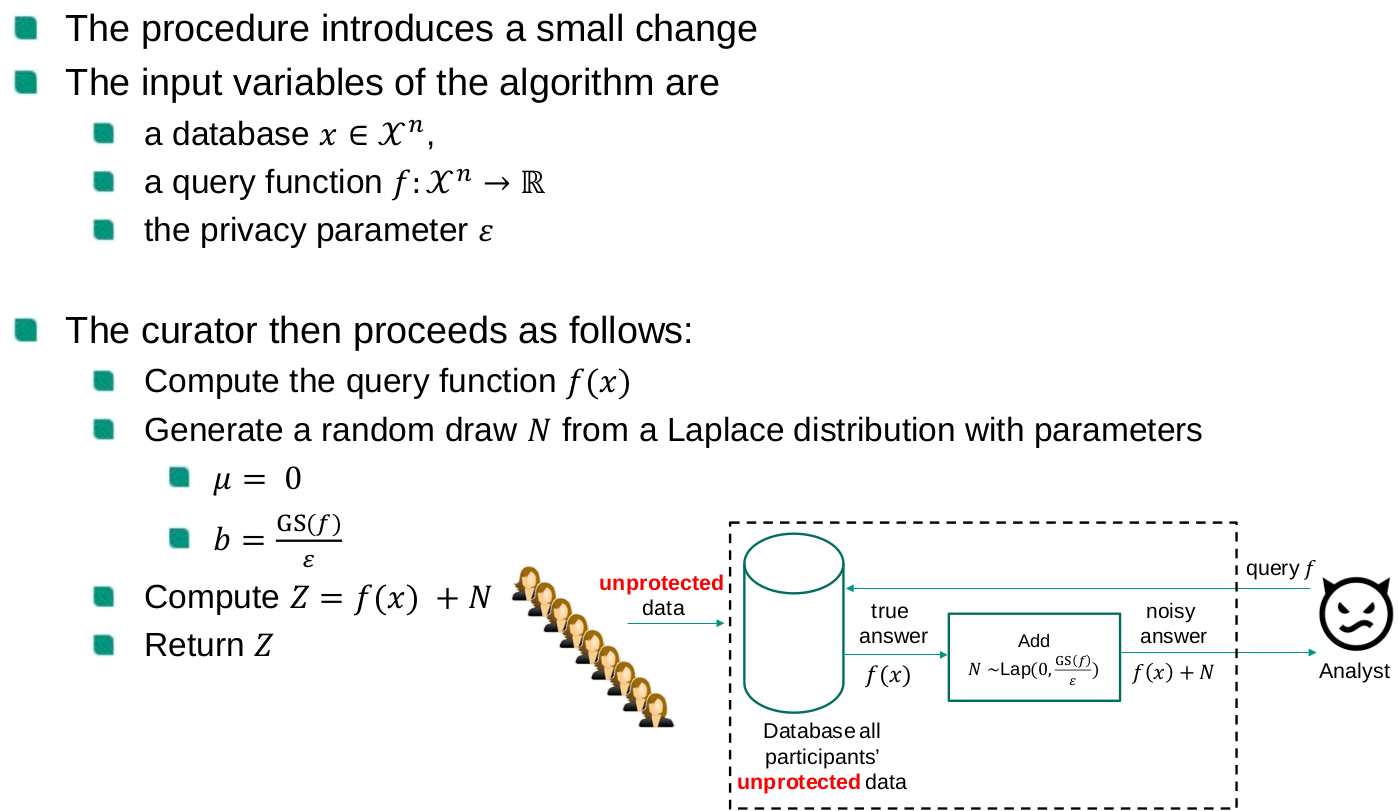
Laplace mechanism
Post-processing theorem
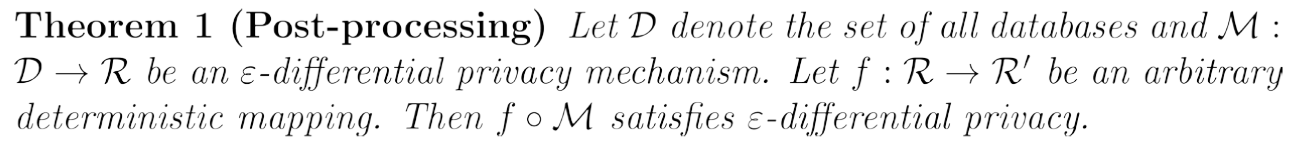
Composability
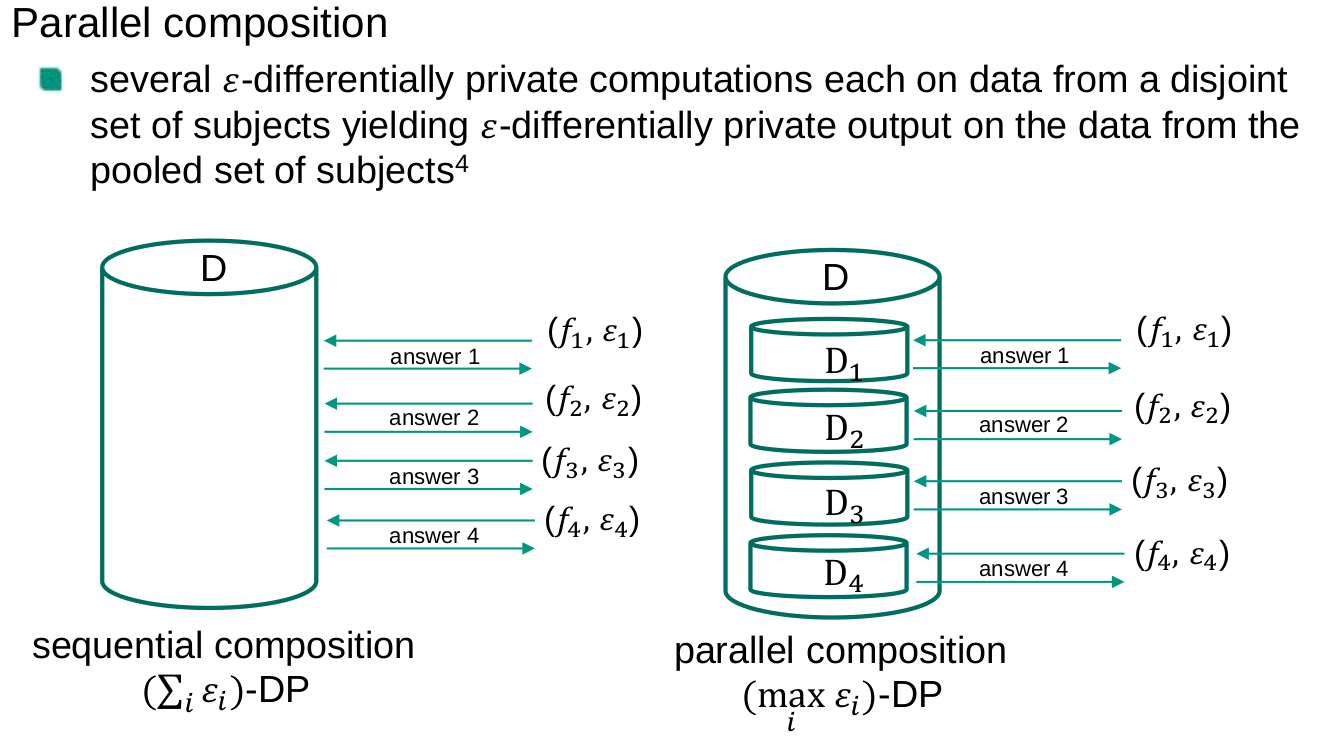
A privacy model is composable if the privacy guarantees of the model are preserved (possibly to a limited extent) after repeated independent application of the privacy model. From the opposite perspective, a privacy model is not composable if multiple independently data releases, each of them satisfying the requirements of the privacy model, may result in a privacy breach
Sequential composition

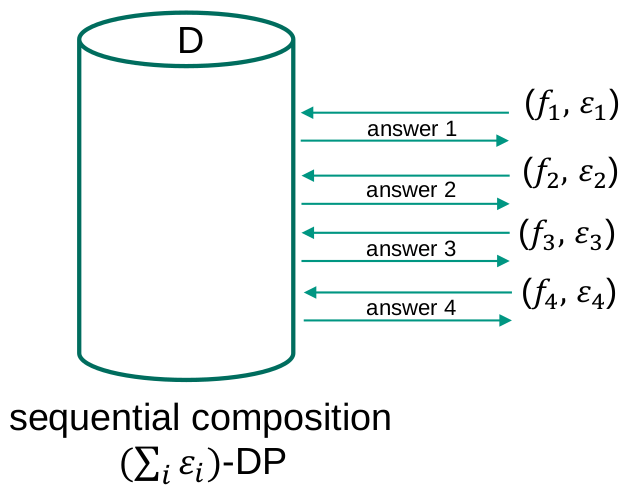
Parallel composition
Exponential mechanism

Utility of the exponential mechanism
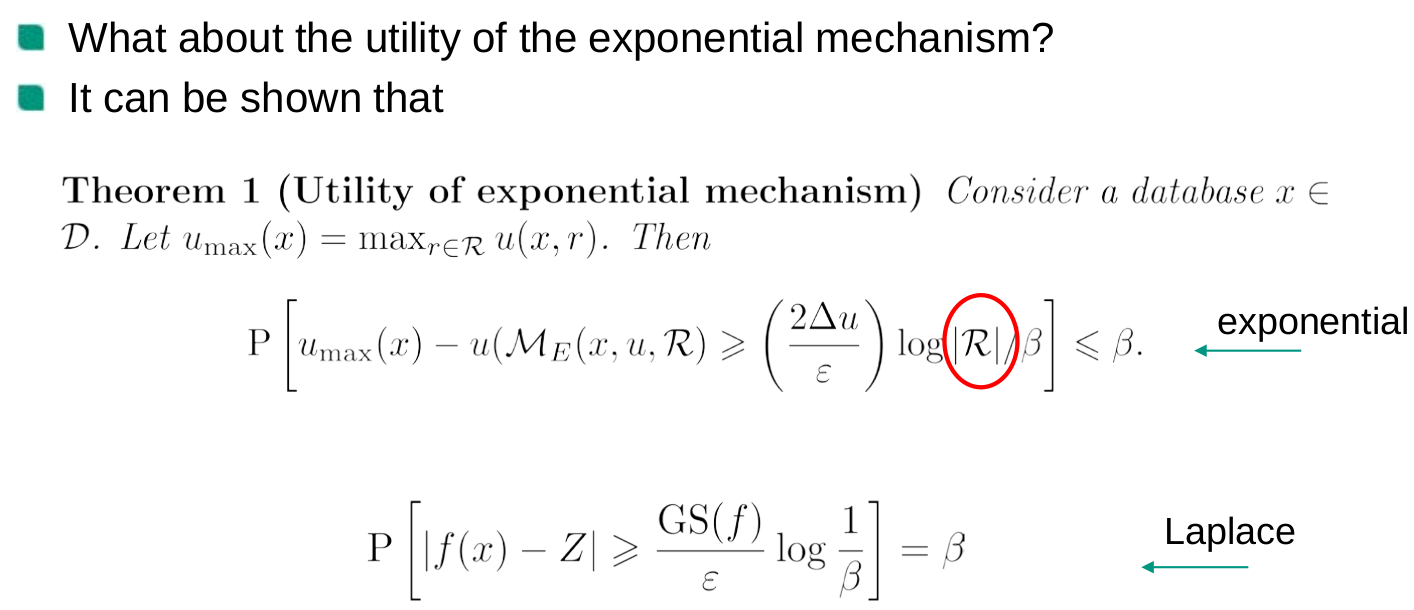
Query forgery

Privacy Notions in Trajectory Data
Challenges of Trajectory Data Privacy
Sparse data, where only a few data points are sufficient to identify someone
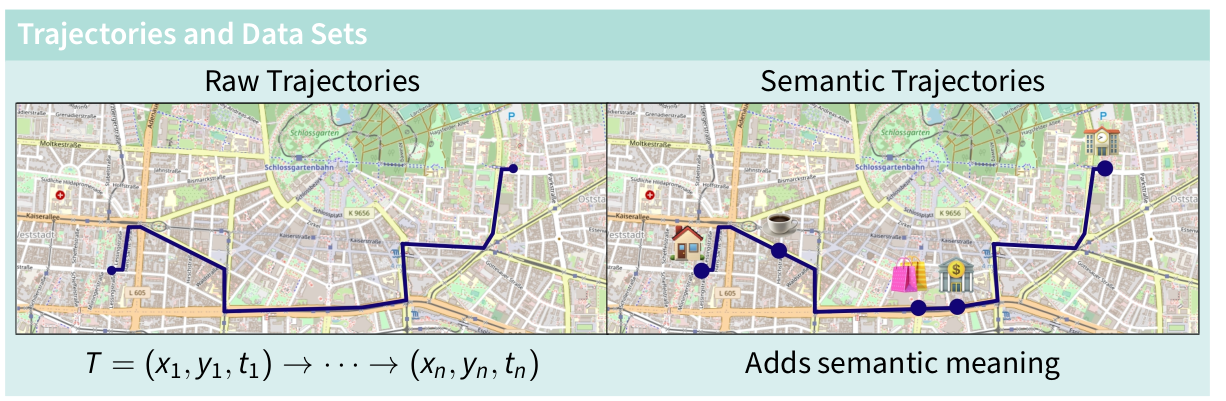
Ways to model trajectories
Problems of Syntactic Techniques
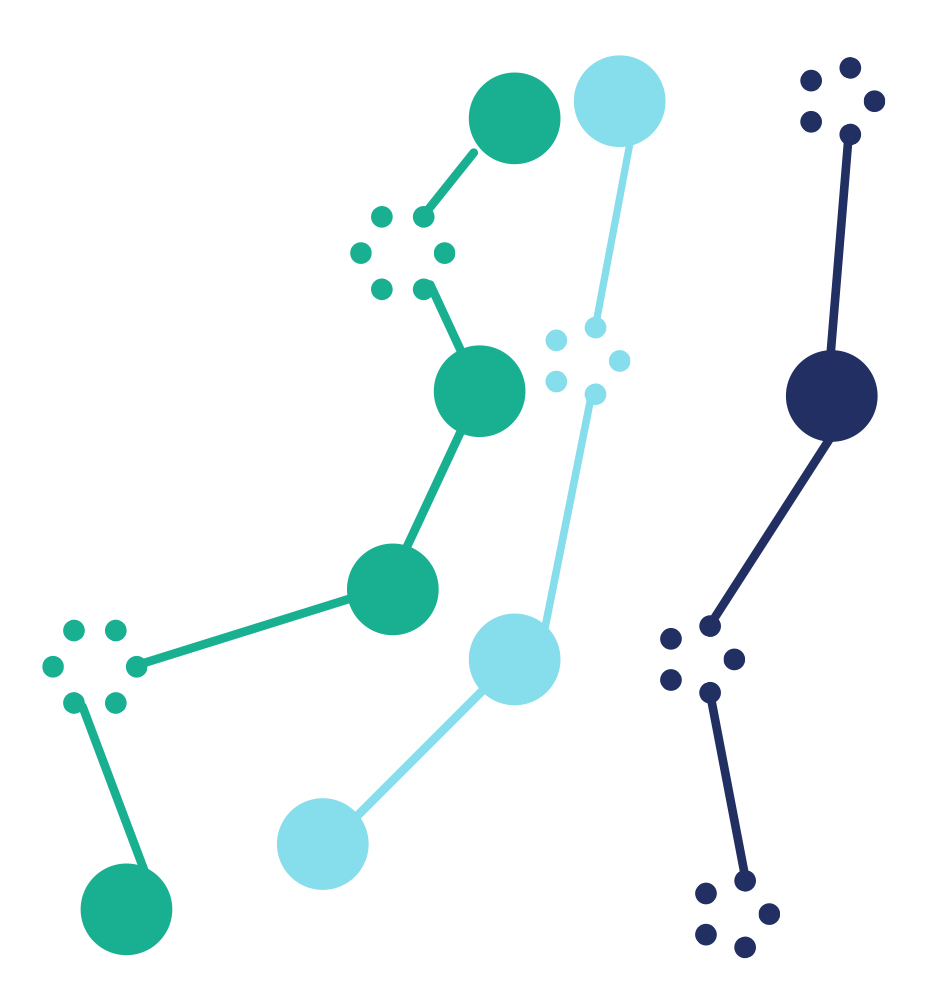
Problem of Suppression
- Drastic reduction of database
- Dangerous when used by itself
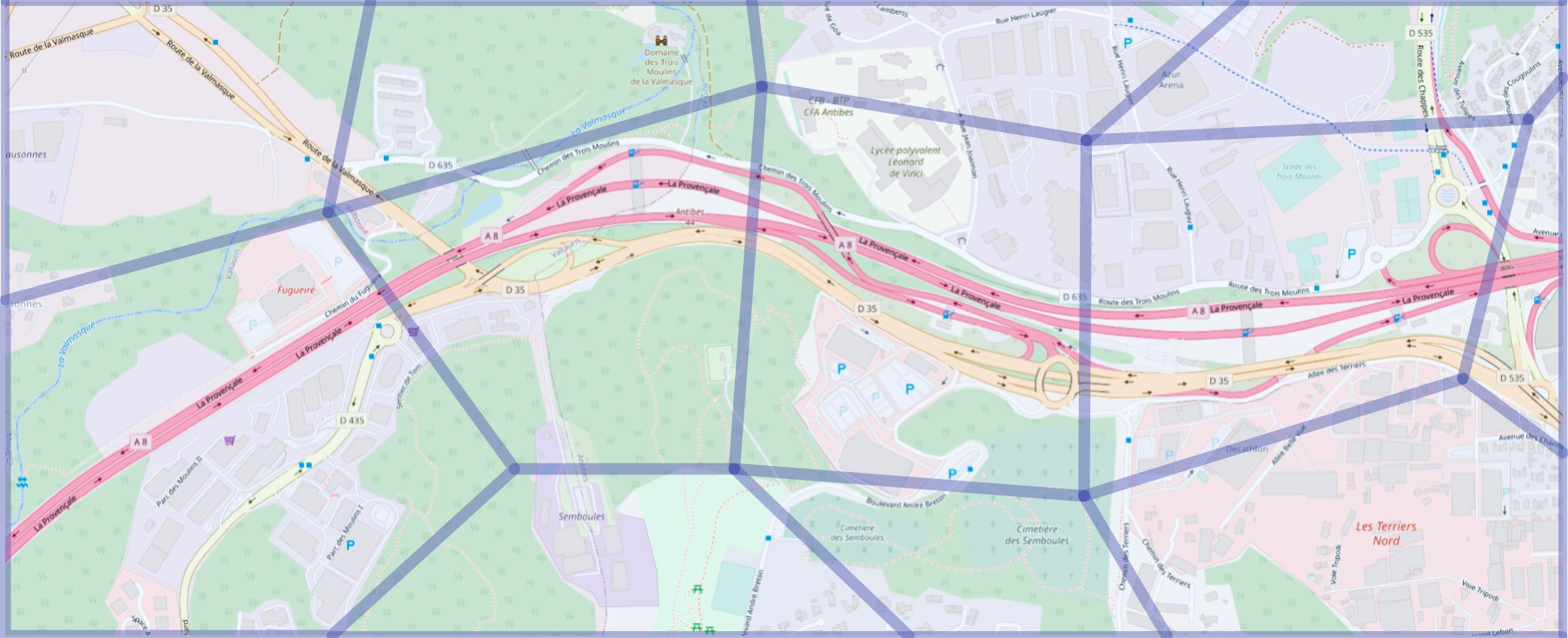
Problem of Generalization
- Not generalizing all dimensions
- Inappropriate regions definition
- Background knowledge attacks
- Drastic reduction of precision
- Dangerous when used by itself
Problem of Masking
- Unpredictable biases
- Impossible trajectories
Semantic Techniques
Privacy Notions in Trajectory Data
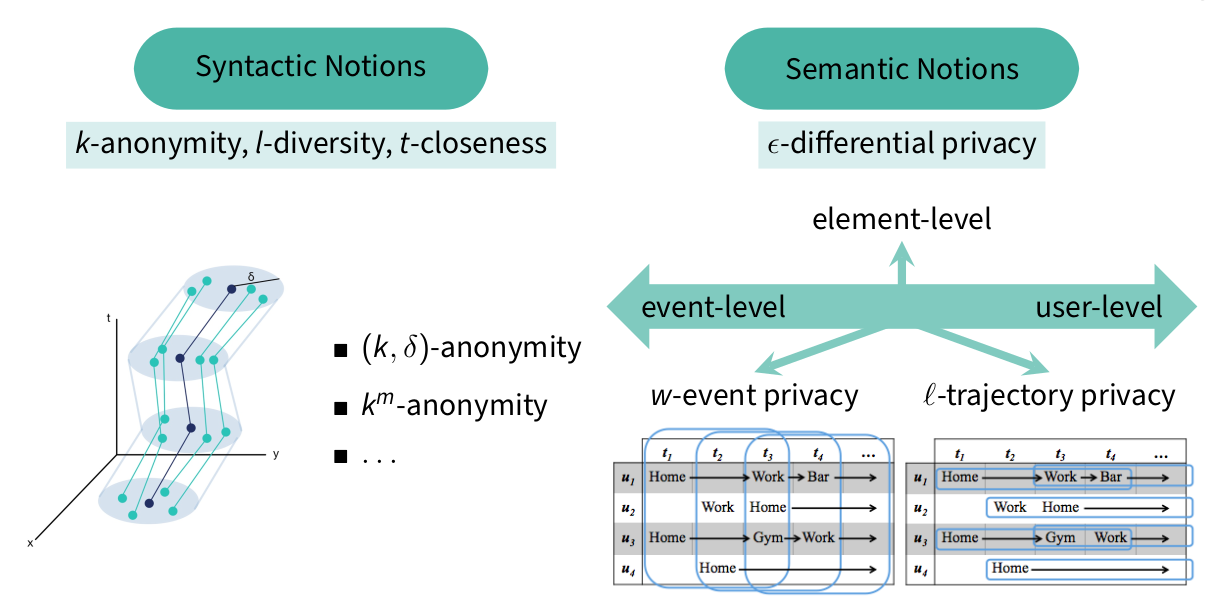
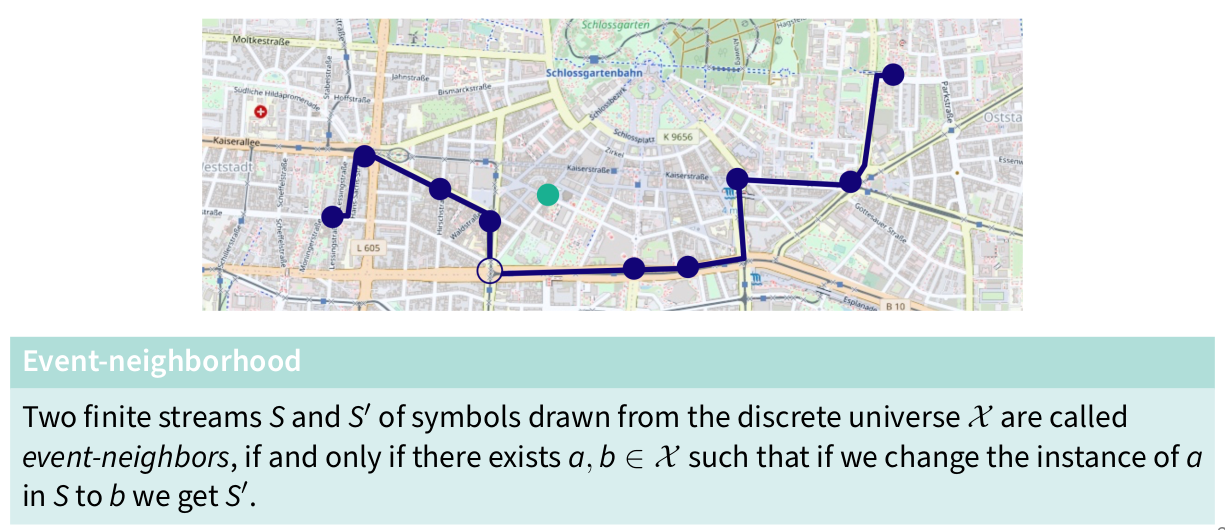
Event-neighborhood
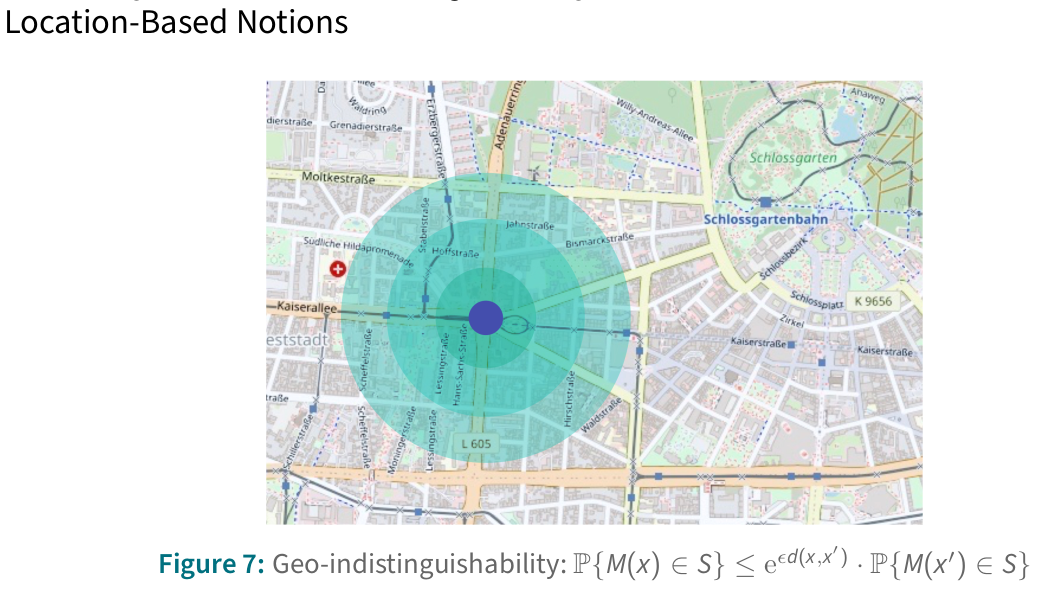
Geo-indistinguishability
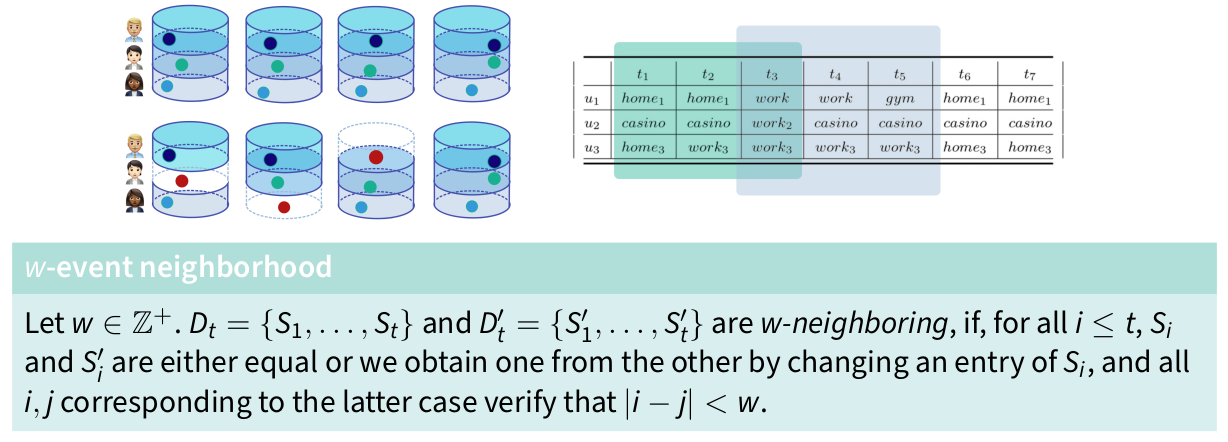
w-event neighborhood
Not allowed to change entries that are far from each other, as in event-neighborhood
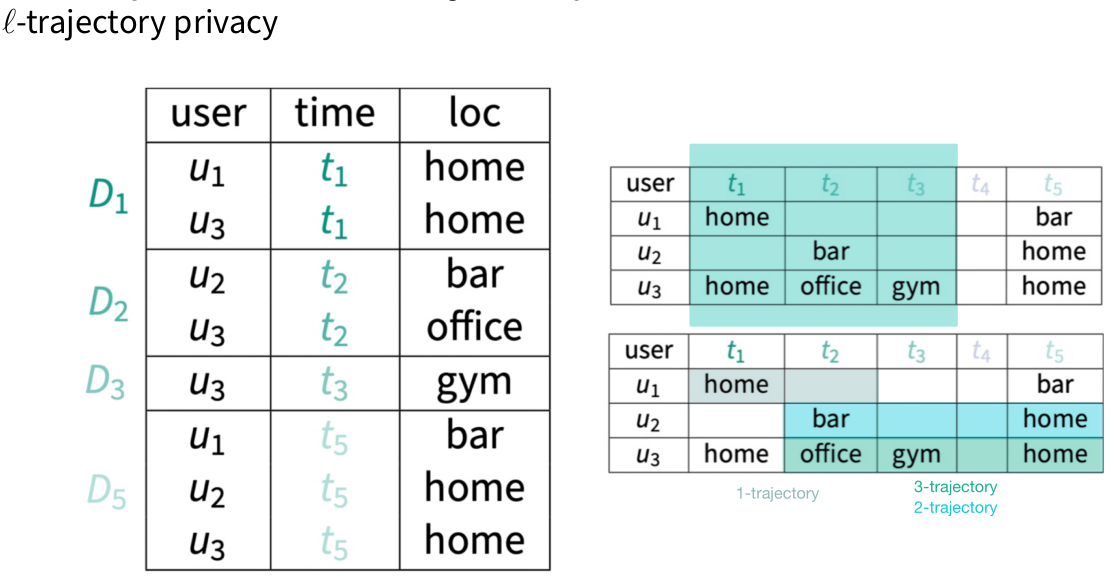
ℓ-trajectory privacy
Distance between users
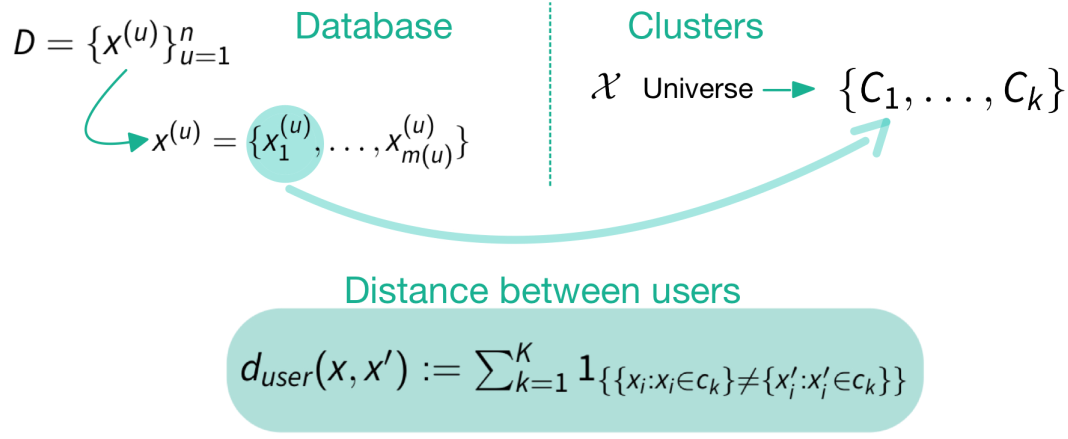

Distance of trajectories
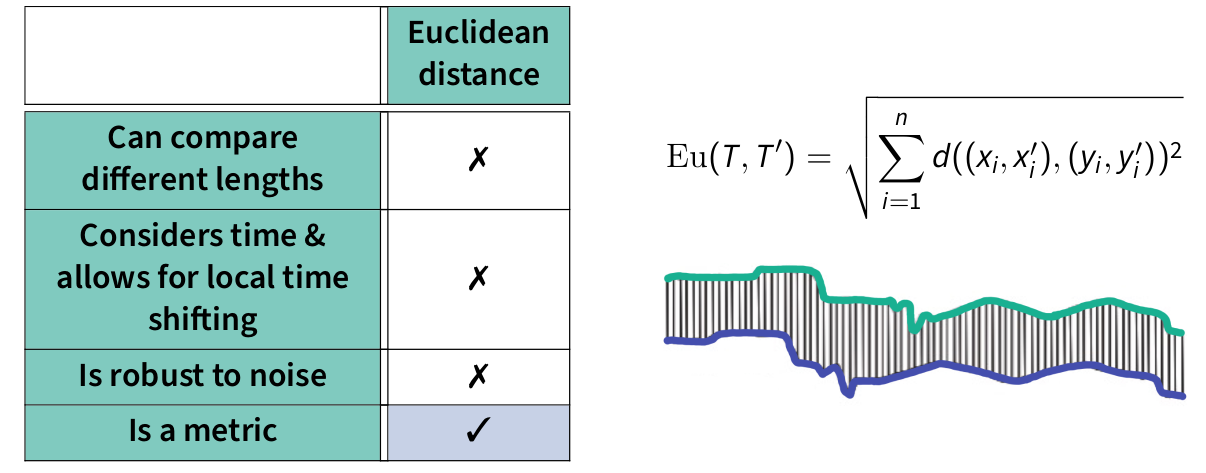
Euclidean distance
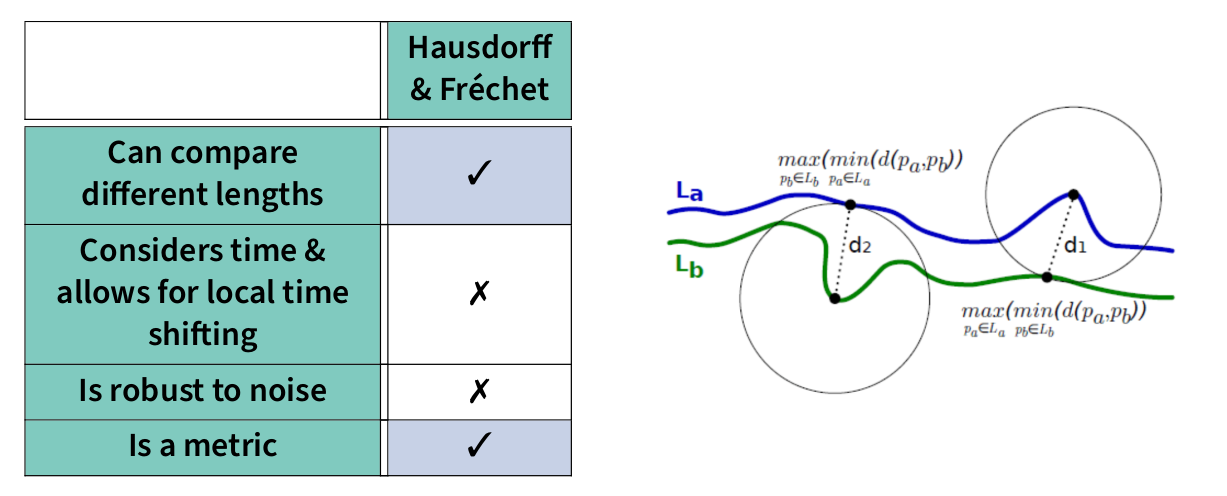
Hausdorff & Fréchet distances
DTW
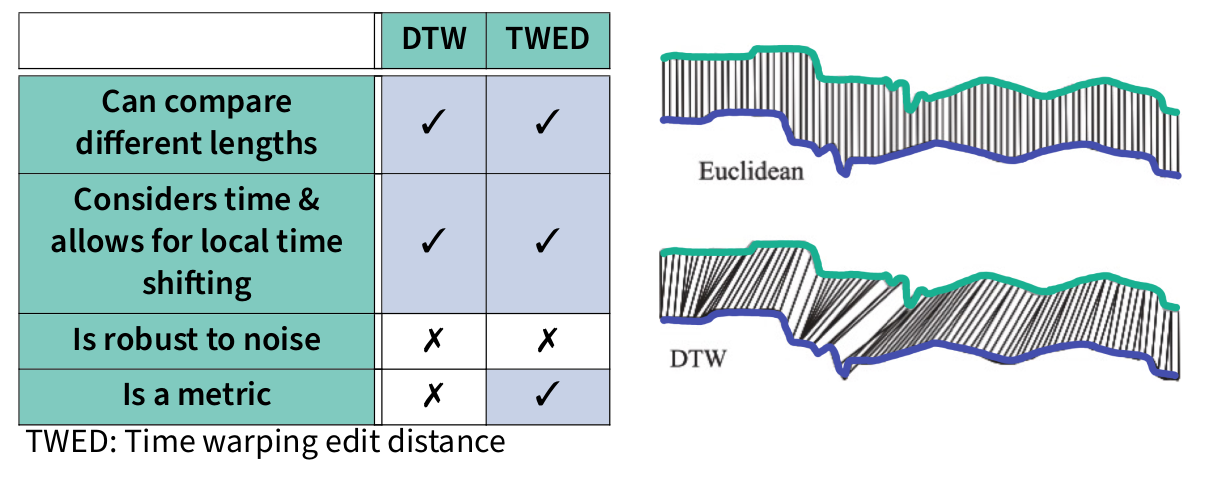
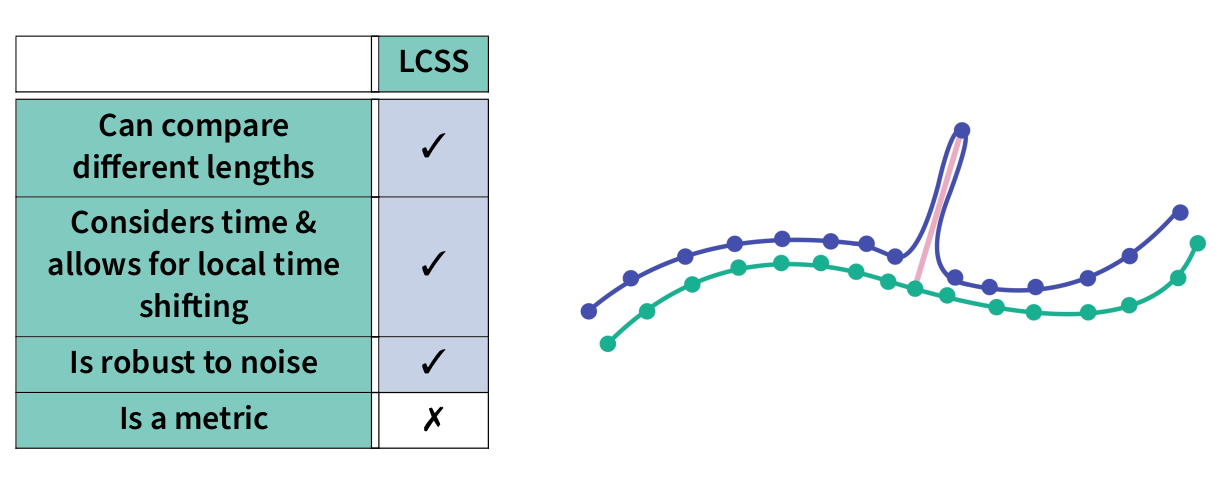
LCSS
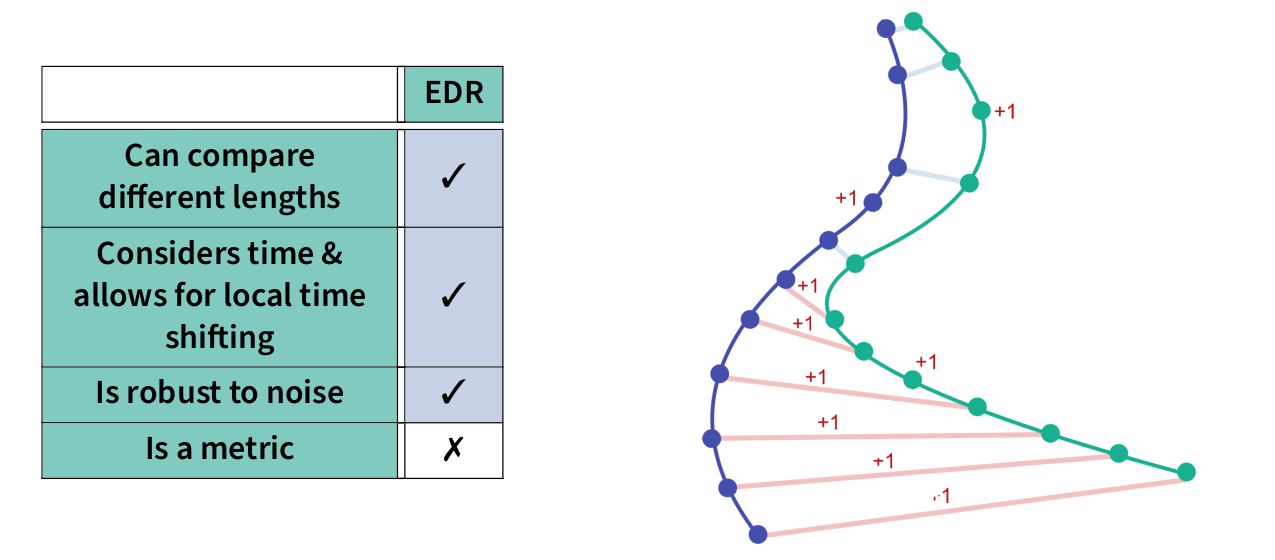
EDR
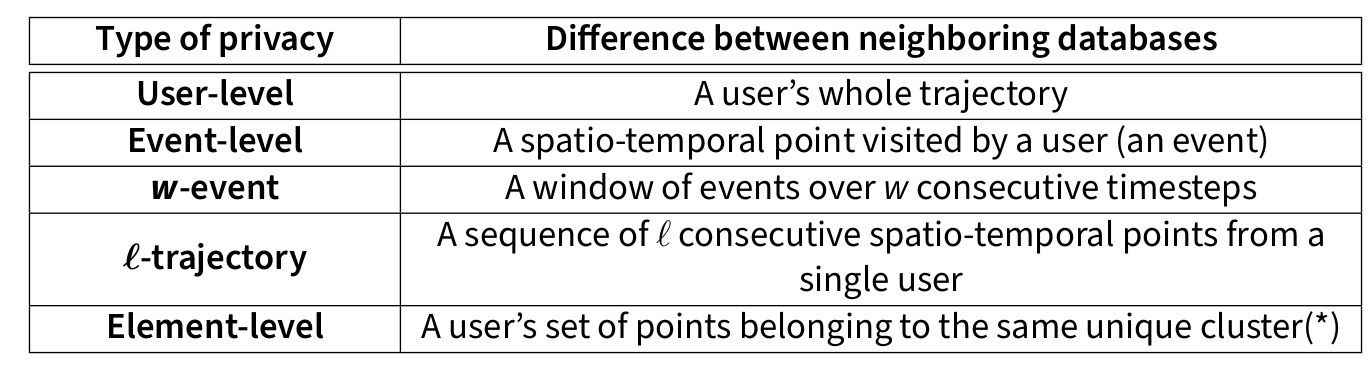
Granularity notions and their concept of neighborhood
Mechanisms Achieving Differential Privacy
ℓ1 -sensitivity

Laplace mechanism
Databases
SDC
Statistical disclosure control (SDC) is the field that protects statistical databases so that they can be released without revealing confidential information that can be linked to specific individuals among those to which the data correspond
SDC vs PPDM vs PIR
- SDC aims to provide respondent privacy
- Privacy-preserving data mining (PPDM) seeks database owner privacy
- Private information retrieval (PIR) aims for user/analyst privacy
External attack
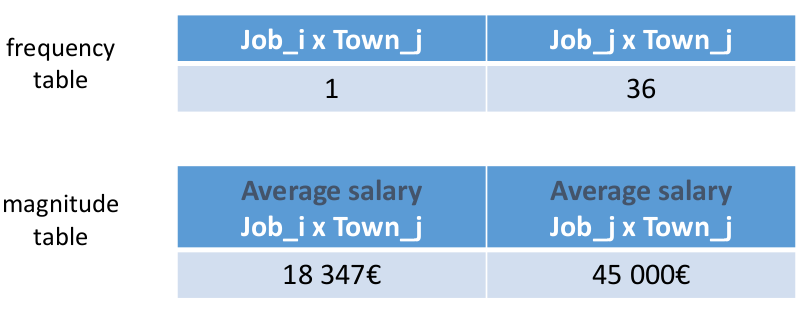
Internal attack
Having two respondents is not enough.
Other respondents can collude.
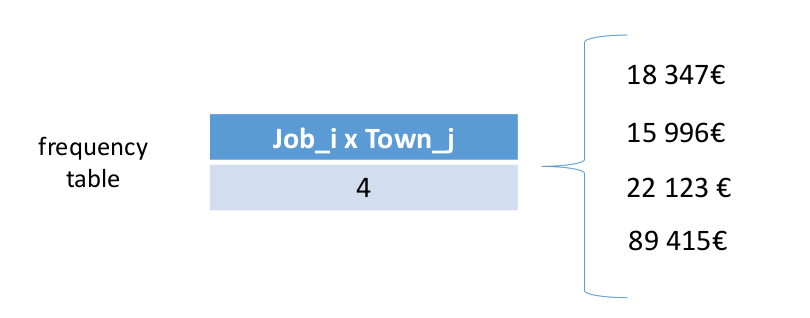
Dominance attack
When one person is known to be an outlier, and the average without them is known, then we can identify the max.
Methods for microdata protection
- Masking methods: generate a modified version of the original data
- Perturbative: modify data
- Noise addition, microaggregation, rank swapping, microdata rounding, and resampling
- Non-perturbative: do not modify the data but rather produce partial suppressions or reductions of detail in the original dataset
- Sampling, global recoding, top and bottom coding, and local suppression
- Perturbative: modify data
- Synthetic methods: generate synthetic or artificial data with similar statistical properties
- Masking methods: generate a modified version of the original data
Output perturbation vs. input perturbation
The Laplace mechanism belongs to a class of mechanisms called output perturbation vs. input perturbation (e.g., RR)