- Wachter Space Blog about Security and Automated Methods/
- Posts/
- Rechnerstrukturen Vorlesungszusammenfassung/
Rechnerstrukturen Vorlesungszusammenfassung
Vorlesungszusammenfassung der Vorlesung Rechnerstrukturen am KIT von Prof. Dr. Karl gehalten von Dr. Lars Bauer und Übungen gehalten von Thomas Becker. Die Klausur hat typischerweise einen hohen Anteil an Wissensfragen und die Bearbeitungszeit ist sehr knapp.
Grundlagen
Einführung
- Zunächst mechanische Rechner
- Platz und Komplexität durch Dualsystem deutlich reduziert
Moore’s Gesetz
Anzahl der Transistoren, die auf einem IC integriert werden können, verdoppelt sich alle 18 Monate. Später angepasst auf alle zwei Jahre.
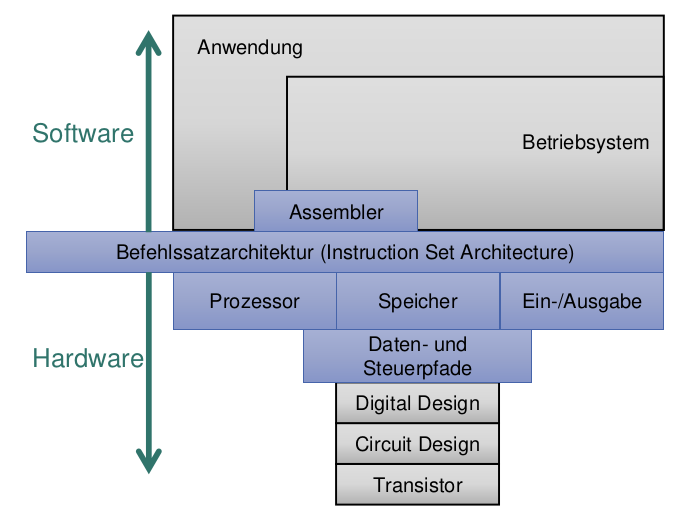
Stufen des Systemaufbaus
Arten von Befehlssatzarchitekturen
Die Befehlssatzarchitektur (ISA) beschreibt welche Instruktionen und Register ein Prozessor zur Verfügung hat
CISC
Complex Instruction Set Computer
- Aus einer Zeit, in der von Hand Assembly geschrieben wurde
- Einzelne Instruktionen implementieren komplexe Funktionalität, nahe an Konstrukten höherer Sprachen
- Mikroprogrammierte Implementierung des Steuerwerks
- Variables Befehlsformat und Befehlslänge
RISC
Reduced Instruction Set Computer
- Nur grundsätzliche Maschinenbefehle
- Einheitliches und festes Befehlsformat
Load/Store-Architektur
- Befehle arbeiten auf Registeroperanden
- Explizite Lade- und Speicherbefehle
- Einzyklus Maschinenbefehle
- Ermöglicht Compileroptimierungen
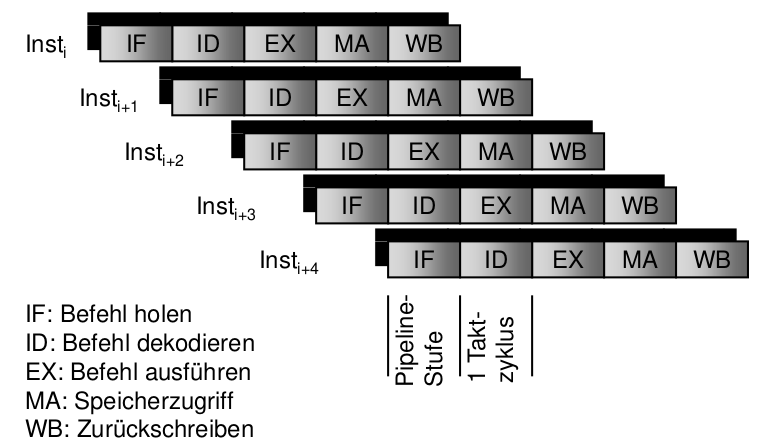
RISC ISA Pipeline
Definition Rechnerarchitektur (Disziplin)
Ingenieurwissenschaftliche Disziplin, die bestehende und zukünftige Rechenanlagen
- beschreibt, 📝
- vergleicht, ⚖️
- beurteilt, 👍👎
- verbessert ❤️🩹 und
- entwirft. ⚙️
Was versteht man unter dem Familienkonzept für Rechnerstrukturen?
Rechnerstrukturen der gleichen Familie teilen sich eine ISA, sodass Programme untereinander Kompatibel sind.
Grundlagen des Entwurfs von Rechenanlagen
Einsatzgebiete für Rechnerstrukturen
- Eingebettete Systeme (IoT)
- Desktop Rechner
- Mobile Rechner
- Server
Definition Leistung P
Energie E, Leistung P und Zeit t
Leistung bezeichnet die aufgenommene bzw. verbrauchte Energie pro Zeit
Was versteht man unter der elektrischen Leistungsdichte?
Verlustleistung pro Fläche (Watt/cm²)
Was ist ein Die?
Klein geschnittener Wafer. Wafer ist meistens kreisrund. Die ist rechteckig.
Entwurfskriterien
Zuverlässigkeit
Bezeichnet die Fähigkeit eines Systems, während einer vorgegebenen Zeitdauer bei zulässigen Betriebsbedingungen die spezifizierte Funktion zu erbringen.
Überlebenswahrscheinlichkeit R(t)
Gibt an, mit welcher Wahrscheinlichkeit ein zu Beginn (also zum Zeitpunkt t=0) fehlerfreies System bis zum Zeitpunkt t ununterbrochen fehlerfrei bleibt
— Anzahl der bis Anzahl der Komponenten, die bis zum Zeitpunkt t überleben
N — Gesamtzahl der Komponenten
MTTF
mean time to failure
- bezeichnet die mittlere Zeitdauer bis zum Ausfall
- Sie wird mithilfe der Überlebenswahrscheinlichkeit R(t) berechnet, Erwartungswert
FIT
(failures in time), Ausfallrate
Anzahl der Ausfälle pro Stunden
MTTR
bezeichnet die mittlere Instandsetzungsdauer
MTBF
mean time between failures
bezeichnet die mittlere Zeitdauer zwischen zwei Ausfällen
(Punkt-)Verfügbarkeit
Ist ein Maß, dass eine reparierbare Einheit zum Zeitpunkt t funktionsfähig ist, im Hinblick auf den Wechsel zwischen fehlerfreien und fehlerbehafteten Zustand
Ausfallrate
- Die Ausfallrate bezeichnet den Anteil der in einer Zeiteinheit ausfallenden Komponenten bezogen auf den Anteil der noch fehlerfreien Komponenten
- Eine Komponente kann zum Zeitpunkt t nur dann ausfallen, wenn sie bis dahin überlebt hat
Niedriger Energieverbrauch bzw. Leistungsaufnahme
- Thermal Design Power (TDP): Maximale Verlustleistung in Watt unter Volllast
- Verlustleistung hängt von Last ab
Berechnung der maximalen Verlustleistung
= Maximal zulässige Versorgungsspannung x höchster Stromverbrauch
- Ausrichten der Kühlung nach dem TDP-Wert
Dynamic Voltage-Frequency Scaling (DVFS)
Techniken zur Verbesserung der Energieeffizienz: Für PMDs, Laptops, oder Server gibt es Perioden mit geringer Aktivität, sodass es nicht notwendig ist, mit höchsten Taktfrequenzen und Spannungen zu arbeiten
Zusammenhang Leistungsaufnahme und Taktfrequenz
Zusammenhang Leistungsaufnahme und Versorgungsspannung
und damit
CMOS-Schaltung: Leistungsaufnahme
- Dynamischer Leistungsverbrauch (bei Zustandsänderung)
Laden oder Schalten einer kapazitiven Last
effektive Kapazität
- a: Wie viele Zustandswechsel (von 1 nach 0 oder umgekehrt) passieren im Schnitt pro Takt
Leistungsverbrauch während des Übergangs am Ausgang in einem CMOS Gatter, wenn sich die Eingänge ändern. Während des Wechsels des Eingangssignals tritt eine überlappende Leitfähigkeit der nMOS und pMOS-Transistoren auf.
- : mittlerer Strom während des Wechsels des Eingangssignals
- Bei CMOS konzeptuell nicht vorhanden
Leistungsverbrauch durch Kriechströme
Bei realen CMOS-Schaltungen kommt zu dem Stromfluss beim Wechsel des logischen Pegels ein weiterer ständiger Stromfluss hinzu: Leckströme (Leakage)
- Widerstände zwischen den Leiterbahnen sind nicht unendlich hoch
- Transistoren sperren nicht perfekt
- Leckströme wachsen mit zunehmender Integrationsdichte
- Bei Integrationsdichten mit Strukturen kleiner als 100 nm kann die Leistungsaufnahme aufgrund von Leckströmen nicht mehr vernachlässigt werden
Kosten
- Entwurfskosten und Herstellungskosten: Herstellungskosten sinken im Lauf der Zeit
- Betriebskosten
Kosten eines Dies
Wafer sind rund, da sie gezogene Einkristalle sind. Diese lassen sich nicht anders produzieren.
: Maß für die Komplexität des Herstellungsprozesses
Die Kosten pro Chip wachsen ungefähr mit der Quadratwurzel der Chip-Fläche. Der Entwickler hat einen Einfluss auf die Chip-Fläche und daher auf die Kosten, je nachdem welche Funktionen auf dem Chip integriert werden und durch die Anzahl der I/O Pins
Kosten eines integriertem Schaltkreis (IC)
Randbedingung: Technologische Entwicklung / Performance
- Prozessor
- Strukturbreiten
- Integrationsdichte
- Chip-Fläche
- Speicher
- DRAM Speicherkapazität
- Flash (SSD) (8-10x billiger/Bit als DRAM)
- Magnetspeicherkapazität: 200-300x billiger/Bit als DRAM
- Erreichbare Taktfrequenz
- Flacht ab
- Prozessor
Bewertung von Rechensystemen
Einfache Hardwaremaße
CPU-Zeit einer Programmausführung
Anzahl der ausgeführten Befehle
Anzahl der Zyklen pro Instruktion (Maß für die Effizienz einer Architektur)
Zykluszeit
Instruktionen pro Zyklus
MIPS
Millions of Instructions Per Second
MFLOPS
Es werden nur Fließkommaoperationen gezählt. Kein Kontrollfluss, kein Speicherzugriff
Probleme von einfachen Hardware-Maßzahlen
- Abhängigkeit vom Programm/Befehlssequenz
- Abhängigkeit von ISA: Kein Vergleich unterschiedlicher Architekturen möglich
- MIPS/MFLOPS Angaben von Herstellern oft nur best-case-Annahme: Theoretische Maximalleistung
Benchmarks
SPEC: Organisation, die reale numerische und nicht numerische Programme bestimmt, mit denen ein Benchmark gemacht werden soll.
Spec-Ratio
Geometrisches Mittel der SPECratios
Bedienzeiten und Durchsatz
X = Zugriffszeit + Übertragungszeit
Auslastung
Tatsächlicher Durchsatz durch tatsächliche Auslastung
Monitore
Hardware Monitore
- Performance Counter in der CPU integriert
- Kann von einer API ausgelesen werden
- Aufzeichnung von prozessorinternen Ereignissen
- Unabhängige physikalische Geräte, keine Beeinflussung der Anlage
Software Monitore
Einbau in das Betriebssystem mit Beeinträchtigung der normalen Betriebsverhältnisse
Arten von Aufzeichnungen mit Monitoren
- Kontinuierlich oder sporadisch
- Gesamtdatenaufzeichnung (Tracing)
- Realzeitauswertung
- Unabhängiger Auswertungslauf (Post Processing)
Modelltheoretische Verfahren
Analytische Methoden
- Warteschlangenmodell
Gesetz von Little
Voraussetzung statistisches Gleichgewicht
bzw. Die Komponenten werden in disjunkte Schichten partitioniert
- : mittlere Anzahl von Aufträgen im Wartesystem
- : mittlere Warteschlangenlänge
- : mittlere Ankunftsrate
- : mittlere Verweilzeit (Gesamtheit der Zeit, die ein Auftrag im Wartesystem verbringt)
- : mittlere Bedienzeit (Zeit, die ein Auftrag in der Warteschlange verbringt)
- Petrinetze
- Diagnosegraphen
- Warteschlangenmodell
Arten von Simulationen
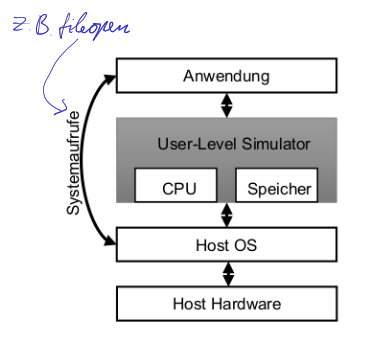
User-Level Simulation
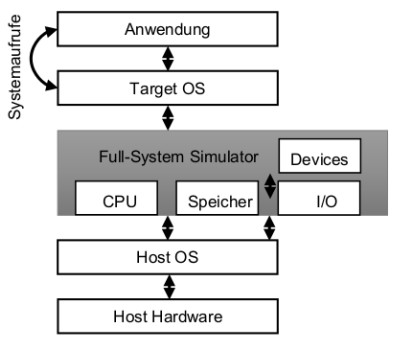
Full-System Simulation
Erkennt zum Beispiel auch fehlenden Hardwaresupport (viele Syscalls sind bottleneck)
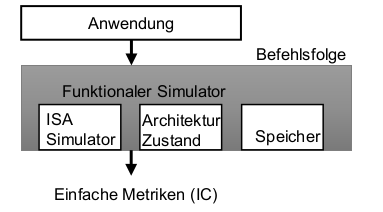
Funktionale Simulation
Modelliert nur die Funktionalität (ohne Berücksichtigung der Mikroarchitektur)
Emulation der ISA (z.B. Unicorn)
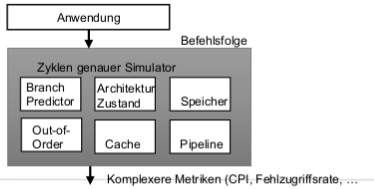
Zyklen genaue Simulation
- Mikroarchitekturblöcke sind parametrisierbar
- Schwer zu bauen
Trace-driven Simulation
Simuliere nur die relevanten Aspekte. z.B. Caches
- Execution-driven Simulation
Zuverlässigkeit, Verfügbarkeit und Fehlertoleranz
Definition Zuverlässigkeit
bezeichnet die Fähigkeit eines Systems, während einer vorgegebenen Zeitdauer bei zulässigen Betriebsbedingungen die spezifizierte Funktion zu erbringen.
Definition Sicherheit
Bezeichnet das Nicht-Vorhandensein einer Gefahr für Menschen oder Sachwerte. Unter einer Gefahr ist ein Zustand zu verstehen, in dem (unter anzunehmenden Betriebsbedingungen) ein Schaden zwangsläufig oder zufällig entstehen kann, ohne dass ausreichende Gegenmaßnahmen gewährleistet sind. Im Gegensatz zur Zuverlässigkeit schließt es die Anwendung mit ein
Definition Fehlertoleranz
Fehlertoleranz bezeichnet die Fähigkeit eines Systems, auch mit einer begrenzten Anzahl fehlerhafter Subsysteme die spezifizierte Funktion (bzw. den geforderten Dienst) zu erbringen. Fehlertoleranz ist eine Technik, die die Zuverlässigkeit eines Systems erhöht.
Fehler Wirkungskette
Fehler / Defekt (fault) → Fehlzustand (error) → Funktionsausfall (failure)
Unterschied Zuverlässigkeit und Fehlertoleranz
Zuverlässigkeit ist ein Optimierungsziel beim Systementwurf, wohingegen Fehlertoleranz eine Technik zur Erhöhung der Zuverlässigkeit ist
Fehlerklassifikationsachsen
Fehlerklassifikation nach Ursachen
- Fehler beim Entwurf
- Herstellungsfehler
- Betriebsfehler
Fehlerklassifikation nach Entstehungsort
- Hardwarefehler
- Softwarefehler
Fehlerklassifikation nach Dauer
- Permanente Fehler
- Temporäre/sporadische/intermittierende Fehler
- Können zu permanenten Fehlern führen
- Transiente Fehler
- Führen nicht zu permanenten Fehlern
Ausfallverhalten: Arten von Ausfällen
- Teilausfall: Von einer fehlerhaften Komponente fallen eine oder mehrere, aber nicht alle Funktionen aus
- Unterlassungsausfall: Eine fehlerhafte Komponente gibt eine Zeit lang keine Ergebnisse aus; wenn jedoch ein Ergebnis ausgegeben wird, dann ist dieses korrekt
- Anhalteausfall: Eine fehlerhafte Komponente gibt nie mehr ein Ergebnis aus
- Haftausfall: Eine fehlerhafte Komponente gibt ständig den gleichen Ergebniswert aus
- Binärstellenausfall: Ein Fehler verfälscht eine oder mehrere Binärstellen des Ergebnisses
Ausfallverhalten: Arten von Systemen
- Fail-stop-System: Ein System, dessen Ausfälle nur Anhalteausfälle sind
- Fail-silent-System: Ein System, dessen Ausfälle nur Unterlassungsausfälle sind
- Fail-safe-System: Ein System, dessen Ausfälle nur unkritische Ausfälle sind
Struktur-Funktions-Modell
- Das Struktur-Funktions-Modell ist ein gerichteter Graph, dessen Knoten die Komponenten und dessen Kanten die Funktionen eines Systems repräsentieren
- Eine gerichtete Kante von der Komponente A zur Komponente B bedeutet, dass A eine Funktion erbringt, die von B benutzt wird
- Komponenten können zu einer Komponentenmenge zusammengefasst und als eine Einheit betrachtet werden
- Komponenten können beliebige HW oder SW Komponenten darstellen
- Prozessoren, Speicher, Teile des Betriebssystems, Teile der Anwendung etc.
- Das Struktur-Funktions-Modell ist ein gerichteter Graph, dessen Knoten die Komponenten und dessen Kanten die Funktionen eines Systems repräsentieren
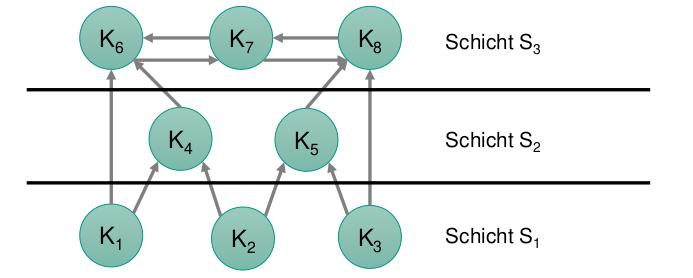
Schichtenmodell
- Ist eine Ausprägung des Struktur-Funktions-Modells
- Die Komponenten werden in disjunkte Schichten partitioniert
- Funktionszuordnungen sind nur von niedrigeren an höhere Schichten (eine Halbordnung) und innerhalb von Schichten möglich
Binäres Fehlermodell
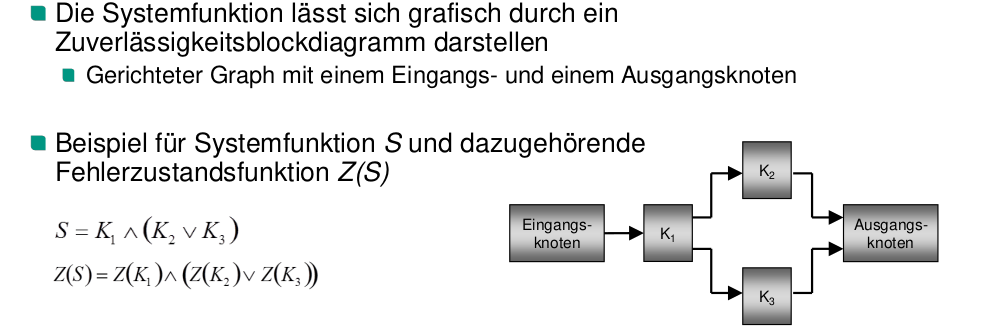
Systemfunktion
- Systemfunktion ist eine bool’sche Formel der Komponenten
- Sie gibt in Abhängigkeiten der Komponenten an, ob das System fehlerfrei ist
- Eine Komponente ist genau dann wahr, wenn sie funktioniert
Zuverlässigkeitsblockdiagramm
Fehlerbaum = Strukturbaum
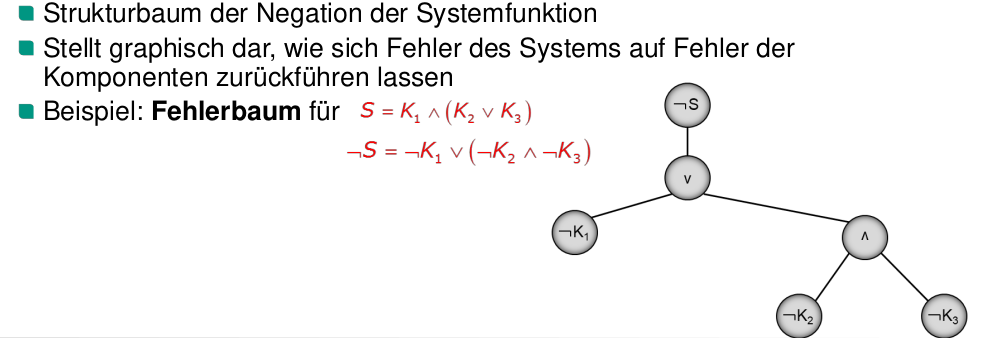
Wozu wird ein Strukturbaum üblicherweise verwendet?
Ein Strukturbaum wird verwendet, um einen Systemfehler auf Fehler der einzelnen Komponenten zurückzuführen.
Badewannenkurve
Badewannenkurve: Ausfallrate über die Lebenszeit eines Systems
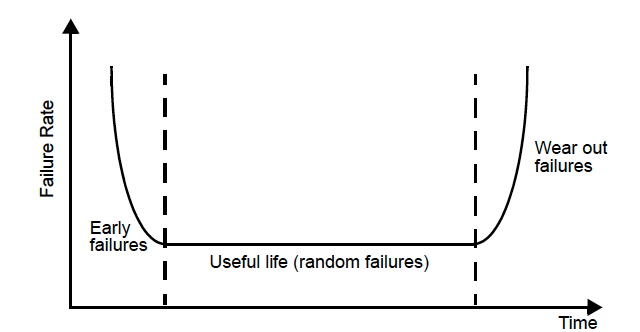
- Frühphase – Ausfallrate exponentiell abfallend (Initialausfälle)
- Betriebsphase – nahezu konstante Ausfallrate
- Spätphase – Ausfallrate exponentiell ansteigend (Alterungseffekte)
Redundanz eines Parallelsystems
Parallelsystem (Einfachsystem mit ungenutzter oder fremdgenutzter Redundanz)

Redundanz eines Seriensystems
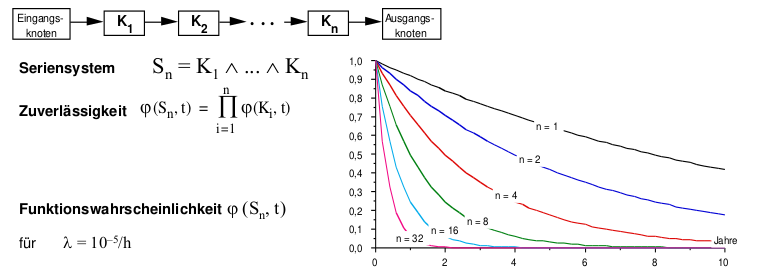
Arten von Redundanz
Dynamische Redundanz
- Bezeichnet das Vorhandensein von redundanten Mitteln, die erst nach Auftreten eines Fehlers aktiviert werden, um eine ausgefallene Nutzfunktion zu erbringen
- Typisch für dynamische strukturelle Redundanz ist die Unterscheidung in Primär- und Ersatzkomponenten (bzw. Sekundär- oder Reservekomponenten)
Ungenutzte Redundanz
Ersatzkomponenten führen keine sonstigen Funktionen aus und bleiben bis zur fehlerbedingten Aktivierung passiv
Gegenseitige Redundanz
Ersatzkomponenten erbringen die von einer anderen Komponente zu unterstützenden Funktionen, die Komponenten stehen sich gegenseitig als Reserve zur Verfügung
Fremdgenutzte Redundanz
Ersatzkomponenten erbringen nur Funktionen, die nicht zum betreffenden Subsystem gehören und im Fehlerfall bei niedrigerer Priorisierung ggf. verdrängt werden
Statische Redundanz
- Bezeichnet das Vorhandensein von redundanten Mitteln, die während des gesamten Einsatzzeitraums die gleiche Nutzfunktion erbringen.
- z.B. m-aus-n-System
m-aus-n-System
Das System ist funktionsfähig, wenn m der n Komponenten funktionieren.
Funktionswahrscheinlichkeit eines m-aus-n-Systems
Binomialkoeffizient
Mit dem Binomialkoeffizienten bestimmt man die Anzahl der Möglichkeiten aus einer Menge mit n Elementen, eine Teilmenge mit k Elementen auszuwählen. Das Ziehen selbst erfolgt ohne Zurücklegen und ohne Beachtung der Reihenfolge
Formen des Parallelismus und Klassifizierung von Rechnerarchitekturen
Nebenläufigkeit
Eine Maschine arbeitet nebenläufig, wenn die Objekte vollständig gleichzeitig abgearbeitet werden.
Pipelining
Pipelining auf einer Maschine liegt dann vor, wenn die Bearbeitung eines Objektes in Teilschritte zerlegt und diese in einer sequentiellen Folge (Phasen der Pipeline) ausgeführt werden. Die Phasen der Pipeline können für verschiedene Objekte überlappt abgearbeitet werden. (Bode, 95)
Ebenen der Parallelität
- Programmebene
- Beispiel Unix-Pipeline
- Prozessebene
- Programm wird in Anzahl parallel ausführbarer Prozesse zerlegt
- Synchronisation und Kommunikation
- Blockebene
- Threads
- Anweisungsblöcke
- Z.B. Innere und äußere parallele Schleifen in FORTRAN-Dialekten oder MPI
- Anweisungs- oder Befehlsebene
- Umordnen und Parallelisieren der Befehle durch Compiler und CPU
- Suboperationsebene
- Elementare Anweisung wird durch Compiler oder durch die Maschine in Suboperationen aufgebrochen, die parallel ausgeführt werden
- Microcode in CISC
- Vektoroperationen
- Elementare Anweisung wird durch Compiler oder durch die Maschine in Suboperationen aufgebrochen, die parallel ausgeführt werden
- Programmebene
Granularität Parallelität
Die Körnigkeit oder Granularität (grain size) ergibt sich aus dem Verhältnis von Rechenaufwand zu Kommunikations- oder Synchronisationsaufwand. Sie bemisst sich nach der Anzahl der Befehle in einer sequentiellen Befehlsfolge.
- Programm-, Prozess- und Blockebene werden häufig auch als grobkörnige (large grained) Parallelität
- die Anweisungsebene als feinkörnige (finely grained) Parallelität bezeichnet.
- Selten bezeichnet mittelkörnig (medium grained) die Parallelität auf Blockebene
Klassifizierung nach M. Flynn
Viele Rechner sind Kombinationen verschiedenen Kategorien, deshalb ist die Klassifizierung wenig aussagekräftig.
- SISD Single Instruction – Single Data
- Uniprozessor
- SIMD Single Instruction – Multiple Data
- Vektorrechner, Feldrechner
- MISD Multiple Instructions – Single Data
- In der Praxis untypisch
- MIMD Multiple Instructions – Multiple Data
- Multiprozessor
- SISD Single Instruction – Single Data
Parallelisierungsprozess
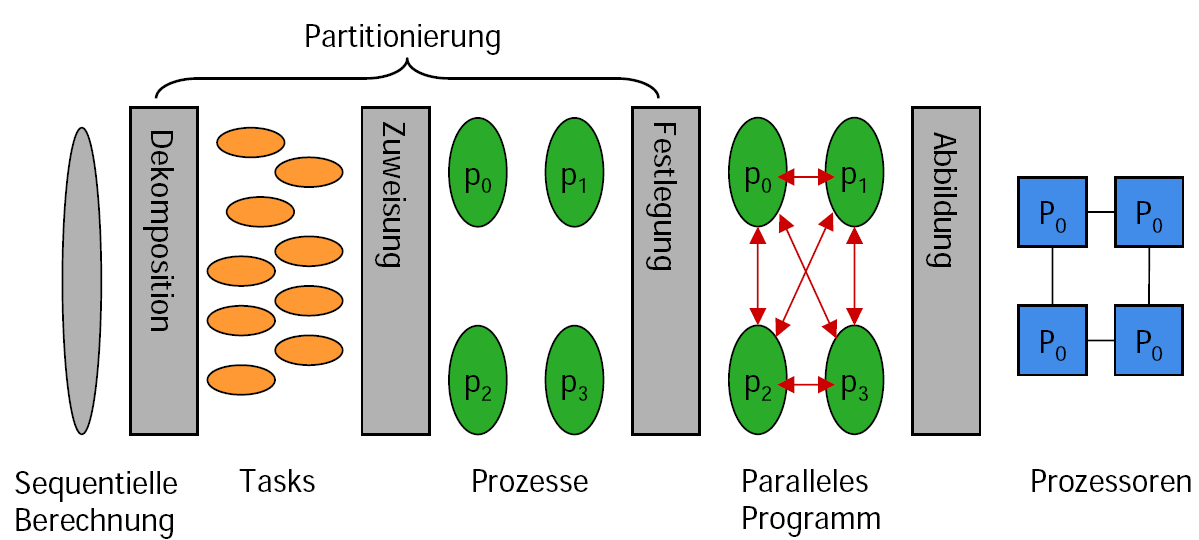
Prozessortechniken
RISC und Superskalarität
Pipelining RISC vs. CISC
Nur RISC erlaubt Pipelining, da sich CISC-Befehle zu unterschiedlich sind, um zerlegt zu werden
Leistungsaspekte einer Pipeline
- Ausführungszeit eines Befehls (Latenz)
- Ausführungszeit T eines Programms
- Sequenzielle Ausführung
- Parallele Ausführung
- Beschleunigung
Vor- und Nachteile Verfeinerung der Pipeline-Stufen
- Weniger Logik-Ebenen pro Pipeline-Stufe
- Erhöhung der Taktrate
- Führt aber auch zu einer Erhöhung der Ausführungszeit (Latenz) pro Instruktion
- „Superpipelining“
Arten von Pipeline-Konflikten
Situationen, die verhindern, dass die nächste Instruktion im Befehlsstrom im zugewiesenen Taktzyklus ausgeführt wird
Strukturkonflikte
- Ergeben sich aus Ressourcenkonflikten
- Die Hardware kann nicht alle möglichen Kombinationen von Befehlen unterstützen, die sich in der Pipeline befinden können
- Beispiel: Gleichzeitiger Schreibzugriff zweier Befehle auf eine Registerdatei mit nur einem Schreibeingang
Datenkonflikte
- Ergeben sich aus Datenabhängigkeiten zwischen Befehlen im Programm
- Konflikte aufgrund einer echten Datenabhängigkeit
- Instruktion benötigt das Ergebnis einer vorangehenden und noch nicht abgeschlossenen Instruktion in der Pipeline
- Konflikte aufgrund von Namensabhängigkeiten
- Wiederverwendung von Registernamen
- Früherer Befehl wird aufgehalten und schreibt aber ins gleiche Register wie späterer Befehl, zwischen denen aber keine Datenabhängigkeit besteht.
- In diesem Fall müssen Registernamen getauscht werden
Steuerkonflikte
Treten bei Verzweigungsbefehlen und anderen Instruktionen, die den Befehlszähler verändern, auf
Auflösung der Pipeline-Konflikte
- Pipeline Stall
- Pipeline Bubble
- Pipeline Flushes
- Umsortierung des Codes
- Forwarding
Speedup durch k-stufigen Pipeline über n Befehle
Parallelismus auf Instruktionsebene
Dynamische vs. statische Nebenläufigkeit
Dynamisch: Der Prozessor sorgt zur Laufzeit für Nebenläufigkeit, z.B. Superskalartechnik
Statisch: Der Compiler wählt nebenläufige Instruktionen für das Programm, der Prozessor führt diese einfach aus, ohne weitere Entscheidungen zu treffen, z.B. VLIW (Very Long Instruction Word), EPIC (Explicitly Parallel Instruction Computer)
Eigenschaften Superskalar-Prozessor
- Viel-stufige Befehlspipeline
- Mehrere voneinander unabhängige Ausführungseinheiten
- Zur Laufzeit werden pro Takt mehrere Befehle aus einem sequenziellen Befehlsstrom den Verarbeitungseinheiten zugeordnet und aufgeführt
- Dynamische Erkennung und Auflösung von Konflikten zwischen Befehlen im Befehlsstrom ist Aufgabe der Hardware
Aufbau Superskalar-Prozessor
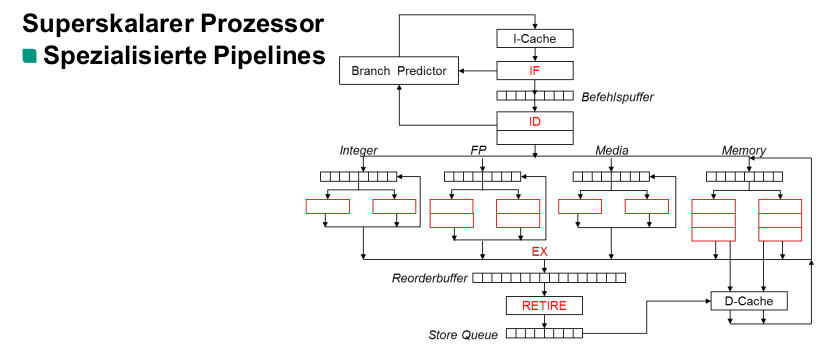
Warum muss ein Reordering stattfinden
- Traps und Interrupts
- Memory mapped IO
Superskalartechnik bei CISC-Architekturen
- Aufteilung der Dekodierung in mehrere Schritte
- Bestimmung der Grenzen der geholten Befehle
- Dekodierung der Befehle
- Generierung einer Folge von RISC-ähnlichen Operationen mithilfe dynamischer Übersetzungstechniken
- Ermöglicht effizientes Pipelining und superskalare Verarbeitung
- Beispiel Intel Pentium- und AMD Athlon-Familie
Superskalarpipeline
Befehlsholphase (IF)
- Holen mehrerer Befehle aus dem Befehls-Cache in den Befehlsholpuffer
- Anzahl der Befehle, die geholt werden, entspricht typischerweise der Zuordnungsbandbreite
- Welche Befehle geholt werden hängt von der Sprungvorhersage ab
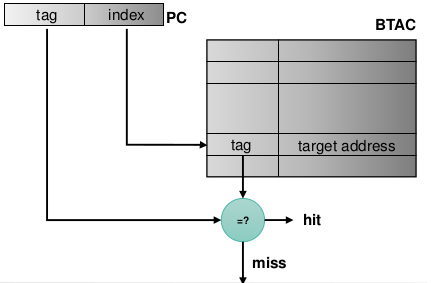
BTAC
Branch Target Address Cache
- Speichert die Adresse der Verzweigung und das entsprechende Sprungziel
- Realisierung als Direct Mapped Cache
- Vor der ID-Phase, deshalb noch nicht klar, um welche Instruktion es sich handelt.
- Tag und Index ist eine Kombination von Adresse der Instruktion und Instruktionsbytes
BHT
- Branch History Table (BHT)
- Festhalten des Verhaltens der Sprungbefehle (T, NT) während der Ausführung des Programms: Prädiktoren
- Vorhersage des Verhaltens eines geholten Sprungbefehls
Statische v.s. dynamische Sprungvorhersage
- Statische Sprungvorhersage (Prädikation)
- Die Richtung der Vorhersage ist für einen Befehl immer gleich
- Für superskalare Prozessorarchitekturen zu unflexibel und nicht geeignet
- Dynamische Sprungvorhersage (Prädiktion)
- Die Verzweigungsrichtung hängt von der Vorgeschichte der Verzweigung ab
- Berücksichtigung des Programmverhaltens
- Genaue Vorhersagen möglich
- Hoher Hardware Aufwand!
- Statische Sprungvorhersage (Prädikation)
2-Bit Prädiktor (Sättigungszähler)
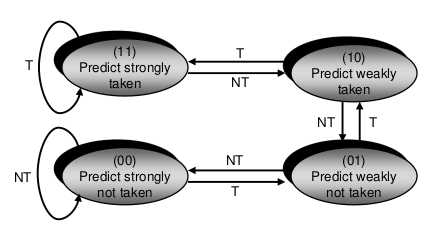
2-Bit Präditor (Hysteresezähler)
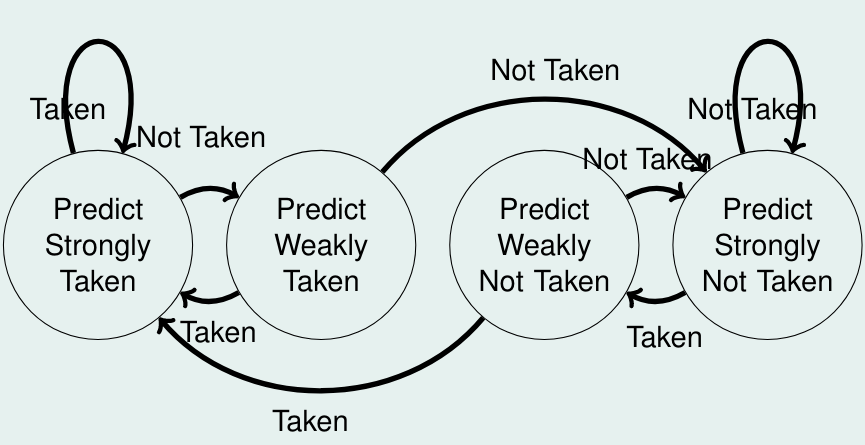
Vermeidet ”Flattern“ zwischen Weakly-Zuständen
Problemfall 2-Bit Prädiktor
Alternierendes Nehmen und Nichtnehmen von Sprüngen (ungerade Zahlen)
(m,n)-Korrelationsprädiktor

Dekodierphase (ID)
Namensabhängigkeit
Treten auf, wenn zwei Instruktionen dasselbe Register, dieselbe Speicherzelle (den Namen) verwenden, aber kein Datenfluss zwischen den Befehlen mit dem Namen verbunden ist Gegenabhängigkeit (Anti dependency)
ADD R2,R3,R4 ... XOR R3,R5,R6Ausgabeabhängigkeit (Output dependency)
ADD R2,R3,R4 ... XOR R2,R5,R6
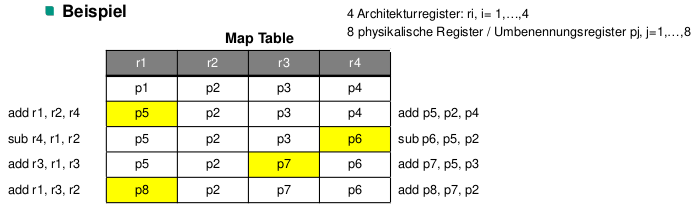
Registerumbenennung
- Dynamische Umbenennung der Operanden- und Ergebnisregister
- Abbildung der nach außen hin sichtbaren Architekturregister in interne physikalische Register
- Zur Laufzeit wird für jeden Befehl das jeweils spezifizierte Zielregister auf ein noch nicht belegtes physikalisches Register abgebildet
- Nachfolgende Befehle, die dasselbe Architekturregister als Operandenregister verwenden, erhalten das entsprechende physikalische Register
- Anzahl der Umbenennungsregister kann die Anzahl der Architekturregister überschreiten
- Auflösen von Konflikten aufgrund von Namensabhängigkeiten
Zuordnungsphase (Dispatch)
- Zuführung der im Befehlsfenster wartenden Befehle zu den Ausführungseinheiten
- Dynamische Auflösung der Konflikte aufgrund von echten Datenabhängigkeiten und Ressourcenkonflikten
Echte Datenabhängigkeit
- Ein Befehl j ist datenabhängig von einem Befehl i, wobei der Befehl i im Programm vor dem Befehl j steht, wenn eine der folgenden Bedingungen gilt:
- Befehl i produziert ein Ergebnis, das von Befehl j verwendet wird, oder
- Befehl j ist datenabhängig von Befehl k und Befehl k ist datenabhängig von Befehl i (Abhängigkeitskette)
Befehl i: ADD R2,R3,R4 ... Befehl j: SUB R5,R2,R6- Ein Befehl j ist datenabhängig von einem Befehl i, wobei der Befehl i im Programm vor dem Befehl j steht, wenn eine der folgenden Bedingungen gilt:
Reservierungstabellen
Zum Auflösen von Lese-nach-Schreib-Konflikt (Read-After-Write, RAW)
- liegen vor den Verarbeitungseinheiten
- Zuordnung eines Befehls an Umordnungspuffer kann nur erfolgen, wenn ein freier Platz vorhanden ist, ansonsten müssen die nachfolgenden Befehle warten (Ressourcenkonflikt)
Befehlsausführung (Ex)
Fertigstellen (Complete)
- Eine Instruktion beendet ihre Ausführung, wenn das Ergebnis für nachfolgende Befehle bereitsteht (Forwarding, Puffer)
- Completion heißt: eine Befehlsausführung ist „vollständig“
- Erfolgt unabhängig von der Programmordnung!
Rückordnungsstufe (Retire)
- Commitment
- Nach der Vervollständigung beenden die Befehle ihre Bearbeitung (Commitment), d.h. die Befehlsresultate werden in der Programmreihenfolge gültig gemacht
- Ergebnisse werden in den Architekturregistern dauerhaft gemacht, d.h. aus den internen Umbenennungsregistern (Schattenregistern) zurückgeschrieben
Bedingungen für Commitment
- Die Befehlsausführung ist vollständig (Completion)
- Alle Befehle, die in der Programmordnung vor dem Befehl stehen, haben bereits ihre Bearbeitung beendet oder beenden ihre Bearbeitung im selben Takt
- Der Befehl hängt von keiner Spekulation ab
- Keine Unterbrechung ist vor oder während der Ausführung aufgetreten (precise interrupts)
- Commitment
Warum ist Sprungvorhersage schon in IF möglich?
Nachdem der Sprungbefehl das erste Mal dekodiert wurde, wird die Adresse des Sprungbefehls im Branch Target Address Cache gespeichert, wodurch bereits an der Befehlsadresse erkannt werden kann, ob es sich um ein Sprungbefehl handelt.
Backward Propagation of Stalling
Stalling bezeichnet eine Methode zur Auflösung von Pipelinekonflikten durch das Anhalten der Pipeline. Dies verzögert ebenso die Ausführung nachfolgender Befehle, wenn ein Überholen der wartenden Instruktion nicht erlaubt ist. Das Stalling setzt sich also durch die nachfolgenden Instruktionen fort.
Skalarpipeline vs. Supersklarpipeline
Die Superskalar-Technik ermöglicht es (im Gegensatz zur skalaren Befehlspipeline), pro Takt mehrere Befehle den unabhängigen Ausführungseinheiten zuzuordnen und eine gleiche Anzahl von Befehlsausführungen pro Takt zu beenden.
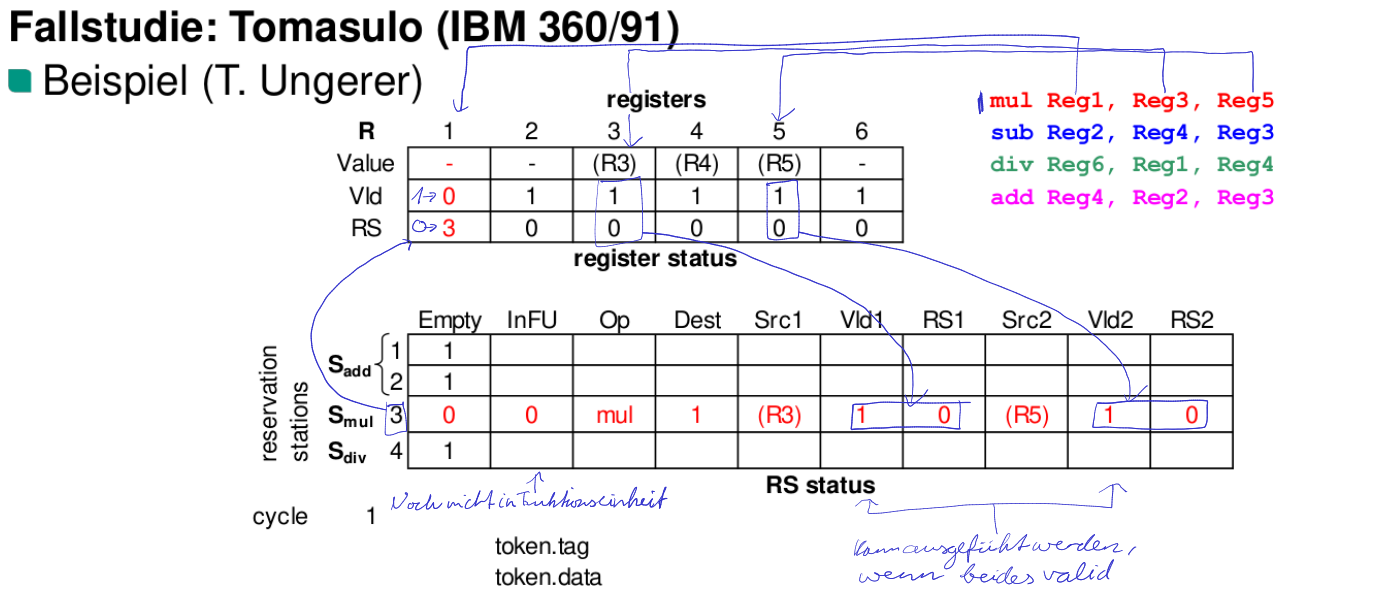
Tomasulo-Verfahren
Zweck des Tomasulo-Verfahrens
Auflösen von Datenkonflikten in der Zuordnungsphase (implementiert im IBM 360/91)
Aufbau des Umordungspuffer/Reservierungstabelle
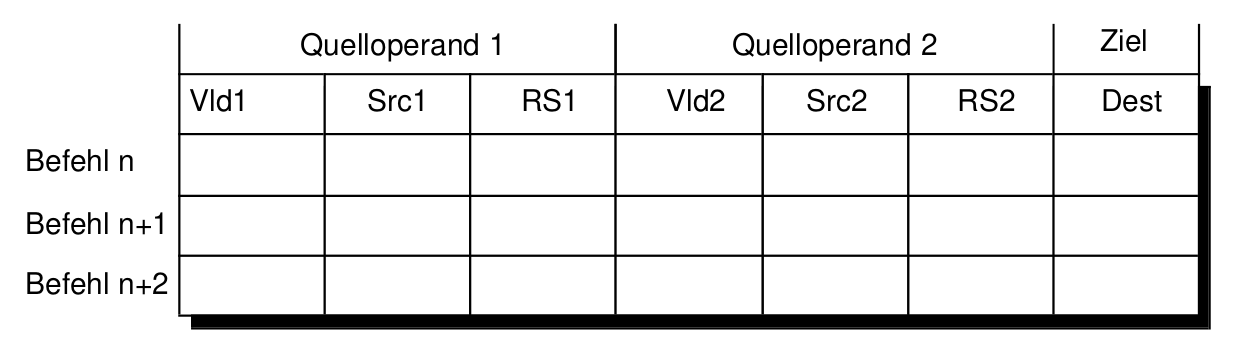
- Die Werte der zwei Quelloperanden (Src1, Src2)
- Jeweils ein Flag für jeden Operanden, das anzeigt, ob ein Operand verfügbar (Valid, Vld) ist (Vld1, Vld2)
- Die Nummern (Namen, Tags) der Reservierungstabellen derjenigen Funktionseinheiten, welche die Quelloperanden für die auszuführende Operation liefern werden (RS1, RS2), falls der Operand noch berechnet wird
- Einen Namen (destination tag) für das Ziel (Dest)
Aufbau der Reservierungstabelle bei Tomasulo
VLIW
Compiler optimiert Zuteilung zu den Recheneinheiten
Parallelismus auf Blockebene
Parallelindex
Wie viele Tasks/Instruktionen werden im Durchschritt gleichzeitig ausgeführt
Wobei die Anzahl der Operationen bei der Ausführung auf Prozessoren angibt.
Beschleunigung (Speedup)
Effizienz
Mehraufwand
Wobei die Anzahl der Operationen bei der Ausführung auf Prozessoren angibt.
Auslastung
- Entspricht dem normierten Parallelindex I(n)
- Gibt an, wie viele Operationen jeder Prozessor im Durchschnitt pro Zeiteinheit ausgeführt hat
Gesetz von Amdahl
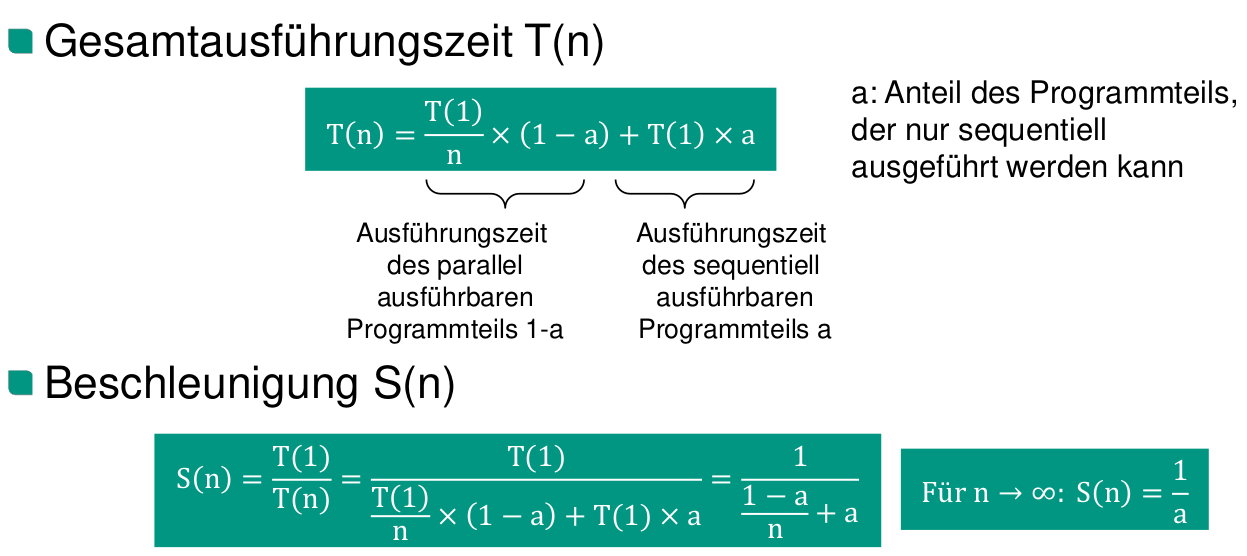
Annahmen für das Gesetz von Amdahl
Amdahl geht von einer festen Problemgröße aus. Damit eine pessimistische Schätzung
Gründe für einen superlinearen Speedup
- Theorie: einen „superlinearen Speedup“ kann es nicht geben
- Jeder parallele Algorithmus lässt sich auf einem Einprozessorsystem simulieren, indem in einer Schleife jeweils der nächste Schritt jedes Prozessors der parallelen Maschine emuliert wird
- Ein „superlinearer Speed-up“ kann aber real beobachtet werden, z.B. bei:
- Parallelem Backtracking (depth-first search, wo es im sequenziellen Fall quasi Zufall ist, ob der richtige Ast gewählt wird)
- Beim Programmlauf auf einem Rechner passen die Daten nicht in den Hauptspeicher des Rechners (häufiger Seitenwechsel), aber: bei Verteilung auf die Knoten des Multiprozessors können die parallelen Programme vollständig in den Cache- und Hauptspeichern der einzelnen Knoten ablaufen
Probleme, die bei Parallelismus auftreten können
- Verwaltungsaufwand (Overhead)
- Steigt mit der Zahl der zu verwaltenden Prozessoren
- Möglichkeit von Systemverklemmungen (deadlocks)
- Möglichkeit von Sättigungserscheinungen
- Können durch Systemengpässe (bottlenecks) verursacht werden
- Verwaltungsaufwand (Overhead)
Vektorrechner und Feldrechnerprinzip
Was versteht man unter einem Vektorrechner?
Unter einem Vektorrechner versteht man einen Rechner mit pipelineartig aufgebautem/n Rechenwerk/en zur SIMD-Verarbeitung von Arrays von Gleitpunktzahlen.
Wie können If-Anweisungen bei Vektorrechnern umgesetzt werden?
Zur Umsetzung von IF-Anweisungen wird das Vektor-Mask-Register eingesetzt, das ermöglicht nur auf den auf 1 gesetzten Einträgen zu arbeiten.
SIMD
Single Instruction Multiple Data
Vektor Stride
Ablegen des Stride-Wertes in ein Allzweckregister
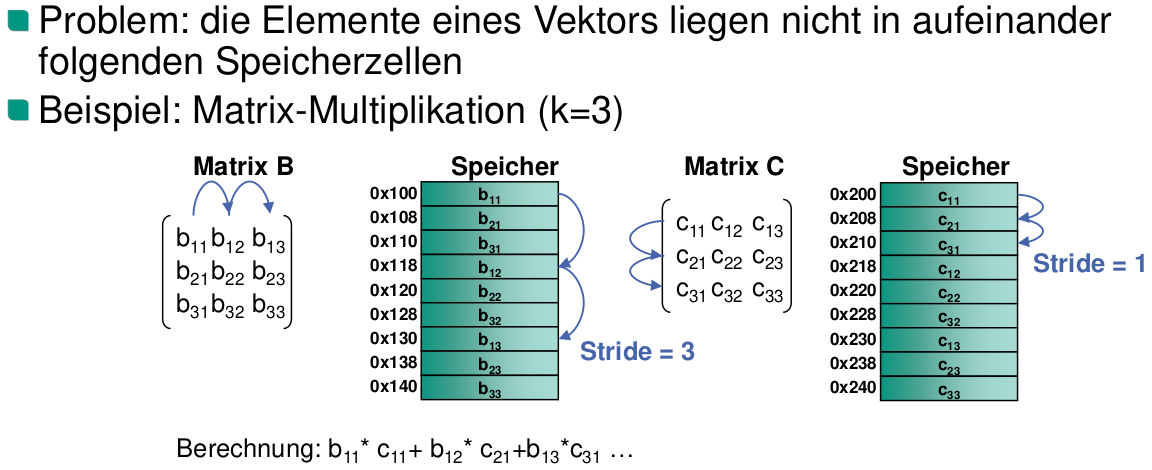
Was ist der Vorteil der Verkettung von Vektor-Pipelines?
Die Ergebnisse einer Pipeline werden sofort der nächsten Pipeline zur Verfügung gestellt, wodurch die Gesamtausführungszeit der Vektoroperationen reduziert wird.
Multiprozessoren
Konfigurationen von Multiprozessoren
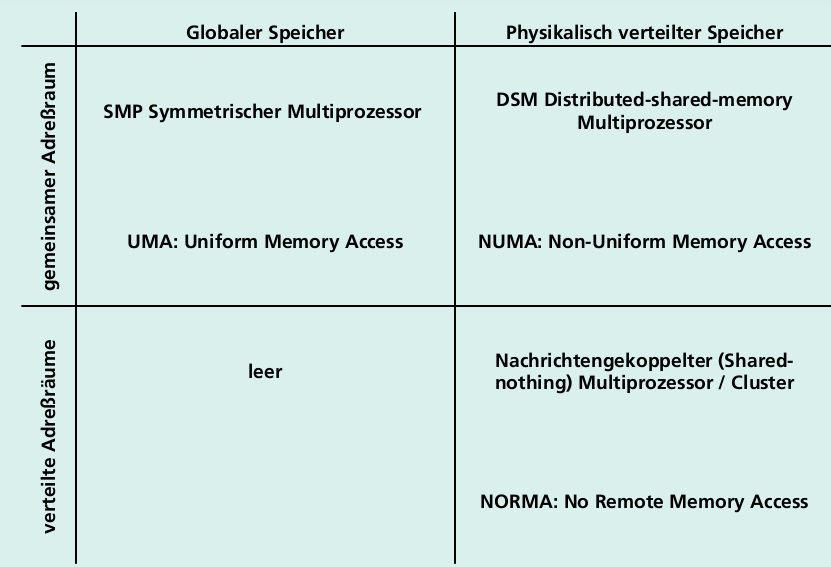
Parallele Architekturmodelle
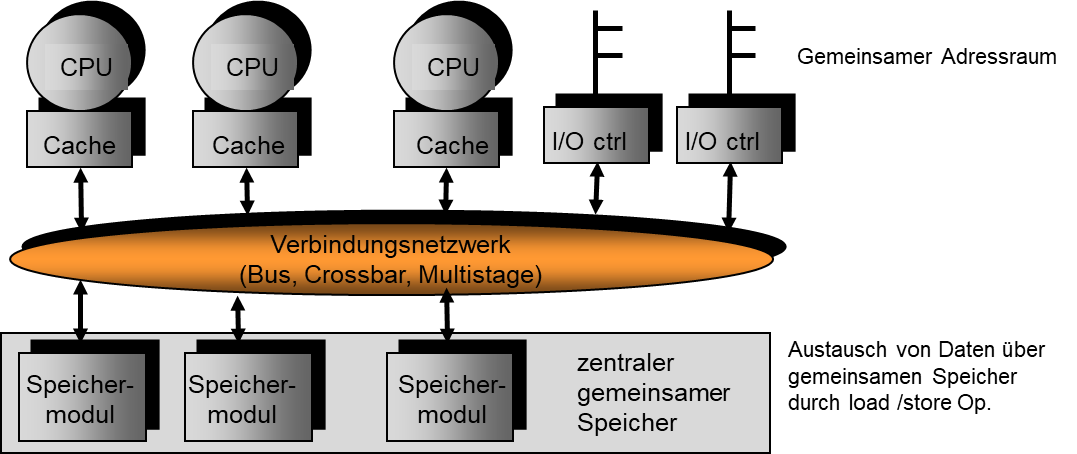
UMA
- UMA: Uniform Memory Access
- Gemeinsamer, zentraler, global adressierter Speicher
- Gleiche Speicherzugriffszeit für jeden Prozessor
- Anlage von Speichermodulen für parallelen Speicherzugriff
- Skaliert nicht beliebig
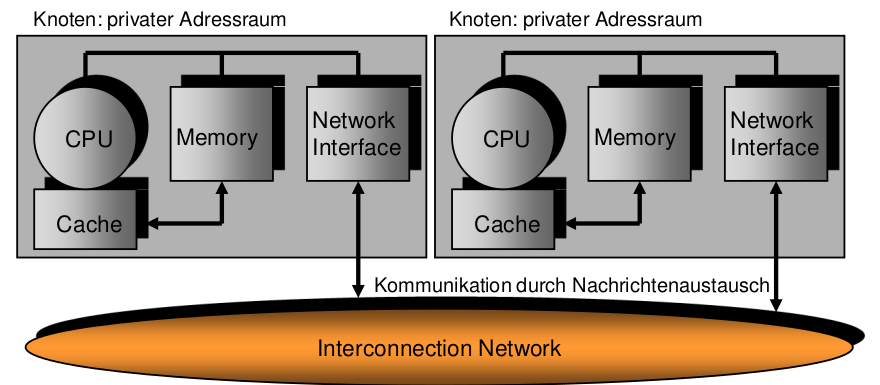
NORMA
- NORMA: No Remote Memory Access
- Nachrichtengekoppelter (Shared-nothing-) Multiprozessor
- Verteilter Speicher, verteilter Adressraum
- Datenkommunikation ausschließlich über Nachrichten möglich
- Skaliert beliebig
NUMA
- NUMA: Non-Uniform Memory Access
- Distributed shared memory (DSM) multiprocessor
- Globaler Adressraum über Knotengrenzen: Zugriff auf entfernten Speicher über load / store Operationen
- Nicht einheitliche Zugriffszeit
- Skaliert deutlich besser als UMA
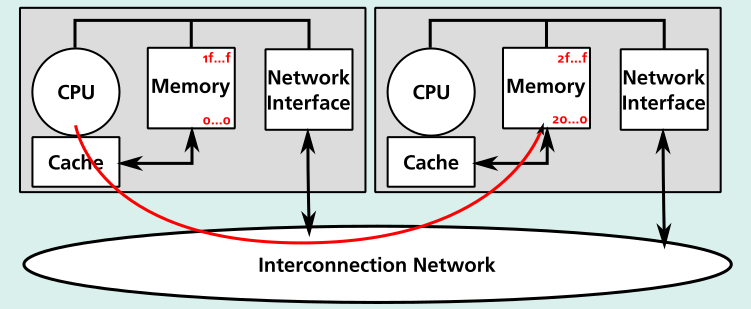
CC-NUMA
- Cache-Coherent Non-Uniform Memory Access
- In HW implementiertes Cache-Kohärenzprotokoll
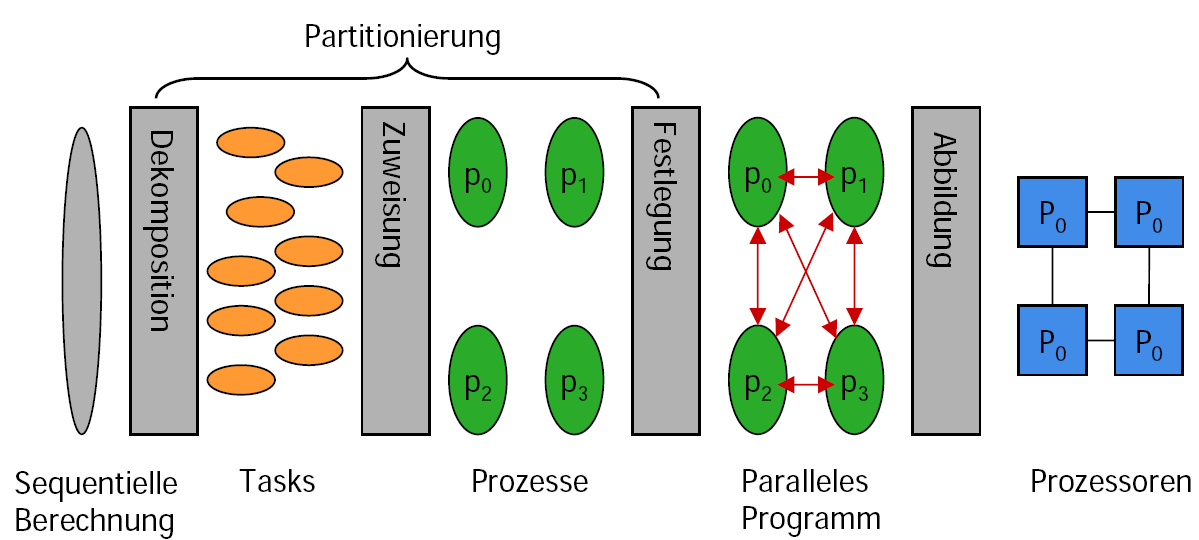
Schritte des Parallelisierungsprozess
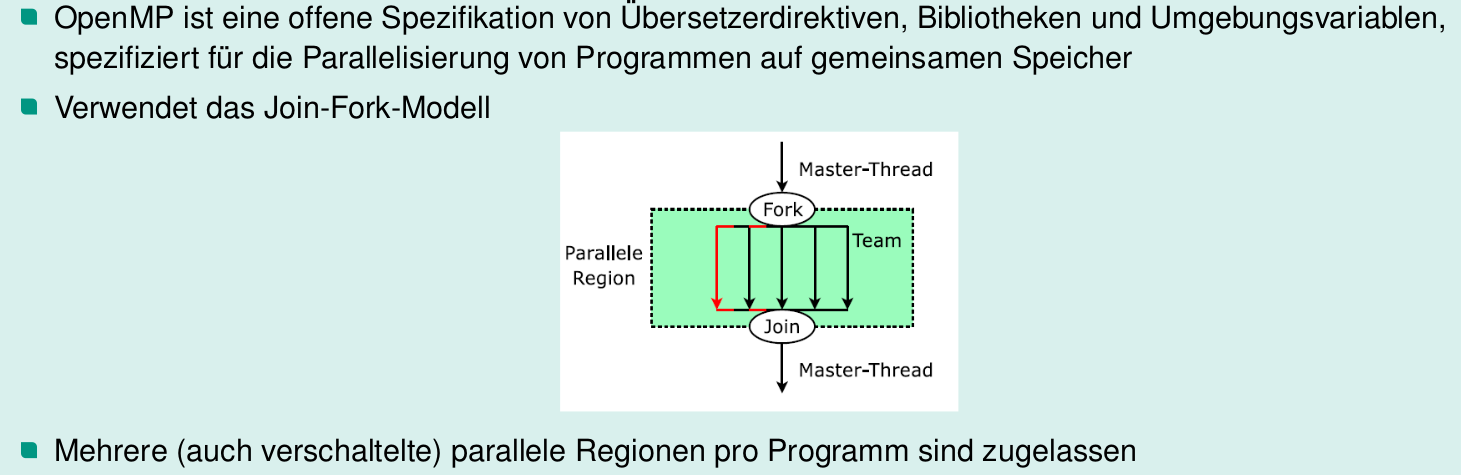
OpenMP
- Shared Memory Programmiermodell
Message Passing Interface (MPI)
- Message Passing Programmiermodell
- MPI ist ein Standard für die nachrichtenbasierte Kommunikation in einem Multiprozessorsystem
- Nachrichtenbasierter Ansatz gewährleistet eine gute Skalierbarkeit
- Bibliotheksfunktionen koordinieren die Ausführung von mehreren Prozessen, sowie Verteilung von Daten, per Default keine gemeinsamen Daten
- Single Program Multiple Data (SPMD) Ansatz
Cycle-by-Cycle Interleaving vs. Block Interleaving
Bei Cycle-by-Cycle Interleaving wird in jedem Takt einer der ausführungsbereiten Kontrollfäden ausgewählt und der nächste Befehle dieses Kontrollfadens ausgeführt. Bei Block Interleaving werden die Befehle eines Kontrollfadens so lange ausgeführt, bis eine Instruktion mit einer langen Latenzzeit ausgeführt wird. Erst dann wird zu einem anderen Kontrollfaden gewechselt.
Grundlagen, Verbindungsnetze, Leistungsfähigkeit
NoC und SAN
- Network on Chip (NoC)
- Chip-Multiprozessor (CMP)
- System / Storage Area Network (SAN)
- Multiprozessor mit verteiltem Speicher (nachrichtenorientierter Multiprozessor)
- Multiprozessor mit gemeinsamem Speicher
- Network on Chip (NoC)
Aufbau eines Pakets

Hierarchische Aufteilung einer Message
- Message: Die zu übertragende Datenmenge
- Message besteht aus ein oder mehreren Paketen
- Paket hat feste Länge
- Header, Payload, Error Code, Trailer
- Paket besteht aus ein oder mehreren Flits (flow control units)
- Flusskontrolle (soll gepuffert oder weitergeschickt werden?) passiert auf Ebene der Flits
- Flit besteht aus ein oder mehreren Phits (physical transfer units)
- Ein Phit ist genauso breit, wie die Links zwischen den Schaltelementen
Arten des Datentransfers (Schaltstrategie)
Durchschalte-/Leitungsvermittlung (Circuit switching)
- Eigenschaft eines Netzes eine direkte Verbindung zwischen zwei oder mehreren Knoten eines Netzes zu schalten
- Die physikalische Verbindung bleibt für die gesamte Dauer der Informationsübertragung (Message) bestehen
- Keine Pakete und Flits erforderlich, sondern nur Phits
- Man kann aber trotzdem Pakete einführen, um eine Zwischenebene für z.B. Fehlerkorrektur/behandlung zu haben
- Phits werden ohne Unterbrechung vom Sender zum Empfänger übertragen
- Phits müssen keine Routing-Information mitführen, da der Weg aufgebaut wird, bevor sie versendet werden
- Vermeidet Routing-Overhead in jedem Schaltelement
- Keine Netzwerkressource auf dem Kommunikationspfad ist für andere Kommunikationen verfügbar, bis die gesamte Message am Ziel angekommen ist
- Keine Pakete und Flits erforderlich, sondern nur Phits
Paketvermittlung
- Pakete werden entsprechend eines Wegefindungsalgorithmus (routing) vom Absender zum Empfänger geschickt
- Zieladresse wird in jedem Knoten (Switch) gelesen und das Paket wird zum nächsten Knoten weitergeleitet, bis die Nachricht das Ziel erreicht
- Je nach Routing-Verfahren kommen die Pakete einer Message nicht zwingend in der ‚richtigen‘ Reihenfolge (in-order) an
- Die Ressourcen eines Schaltelements werden nur solange belegt wie sie benötigt werden
- Falls ein Schaltelement belegt ist und der Weg eines anderen Pakets führt zu diesem Schaltelement, tritt ein Konflikt auf
Flusskontrolle
- Strategie zur Auflösung des Konflikts bei einer Blockierung
- Bestimmt, wann ein Paket von einem Schalter zu einem anderen Schalter übertragen wird
- Flit: Informationseinheit, auf die die Flusskontrolle angewendet wird
Store-and-forward
- Ein Paket wird vollständig von Knoten zu Knoten übertragen
- Alle Teile eines Pakets müssen von einem Knoten empfangen worden sein, bevor ein Teil von ihm zum nächsten Knoten geleitet wird
- Jeder Knoten enthält einen Puffer zum Aufnehmen des vollständigen Pakets
- Ein Paket wird vollständig von Knoten zu Knoten übertragen
(Virtual) Cut-through
- Das ganze Paket passt in einen Flit und wird als ganzes in einem Knoten aufgehalten
- Teile des Pakets (Phits) werden von einem Schaltelement schon weiter geschickt, bevor das komplette Paket von dem Schaltelement empfangen wurde; wie in einer Pipeline
- Im Falle einer Blockierung ist in dem Schaltelement, von dem aus es temporär nicht weiter geht, garantiert genug Puffer für das gesamte Paket reserviert worden
- Der Kopfteil des Pakets enthält die Empfängeradresse und wird in jedem Schaltelement bei der Ankunft des Pakets dekodiert, sodass der einzuschlagende Weg für alle nachfolgenden Phits bestimmt werden kann
- Kopf-Information wird gespeichert, bis das letztes Phit des Pakets weitergeleitet wurde
- Danach wird auch der Puffer wieder freigegeben
Wormhole Switching
- Solange keine Links blockiert sind, mit dem (virtual) Cut-through-Modus identisch
- Falls der Kopfteil der Nachricht auf einen Link trifft, der gerade belegt ist, wird er abgeblockt
- Puffer-Größer im Schaltelement ist ein Vielfaches der Flit-Größe, aber nicht notwendigerweise groß genug für ein ganzes Paket (so wie es beim virtual cut- through wäre)
- Bei blockiertem Header Flit können nachfolgende Flits nachrücken, bis der Puffer des Schaltelements voll ist
- Nachfolgende Flits verbleiben in vorherigen Schaltelementen
- Der Abstand zwischen Header und Tail Flit schrumpft
Buffered Wormhole Switching
Verwendung eines zentralen Puffers, um blockierende Pakete (Flits) zu speichern
Statische Verbindungsnetze
- Nach Aufbau des Verbindungsnetzes bleiben die Verbindungen fest
- Gute Leistung für Probleme mit vorhersagbaren Kommunikationsmustern zwischen benachbarten Knoten
Vollständige Verbindung
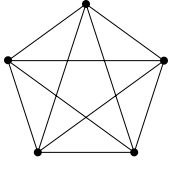
- Höchste Leistungsfähigkeit
- Arbeitet für alle Anwendungen mit allen Arten von Kommunikationsmustern effizient
- Aber: nicht praktikabel in Parallelrechnern
- Netzwerkkosten steigen quadratisch mit der Anzahl der Prozessoren
- Höchste Leistungsfähigkeit
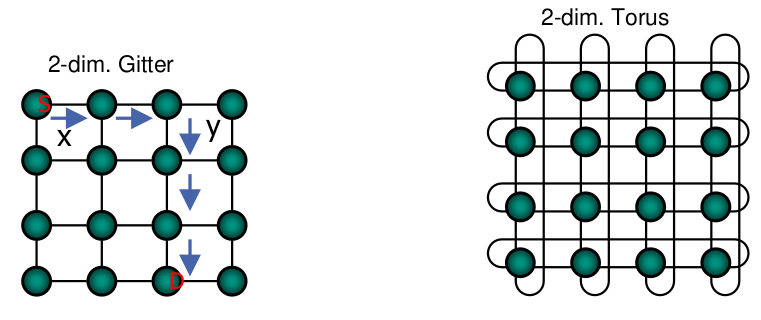
Gitter
1-dimensionales Gitter (lineares Feld, Kette)

- Verbindet N Knoten mit (N-1) Verbindungen
- Endknoten haben den Grad 1, Zwischenknoten den Grad 2 und sind mit benachbarten Knoten verbunden
- Disjunkte Bereiche des linearen Netzwerkes können gleichzeitig genutzt werden, aber es sind mehrere Schritte notwendig, um eine Nachricht zwischen zwei nicht benachbarte Knoten zu verschicken
k-dimensionales Gitter mit N Knoten
Ringe
Ring
- Erhält man, wenn man die Endknoten eines linearen Feldes miteinander verbindet
- Unidirektionaler Ring mit N Knoten
- Nachrichten werden in einer Richtung vom Quellknoten zum Zielknoten verschickt
- Bei Ausfall einer Verbindung bricht die Kommunikation zusammen
Bidirektionaler Ring mit N Knoten
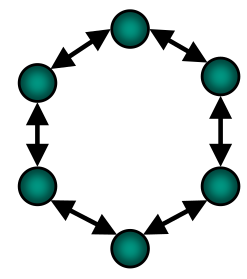
- Der längste Pfad, den eine Nachricht nehmen muss, ist nicht länger als N/2
- Bei Ausfall einer Verbindung bricht die Kommunikation noch nicht zusammen, während zwei Ausfälle von Verbindungen das Netzwerk in zwei disjunkte Teilnetzwerke aufteilen
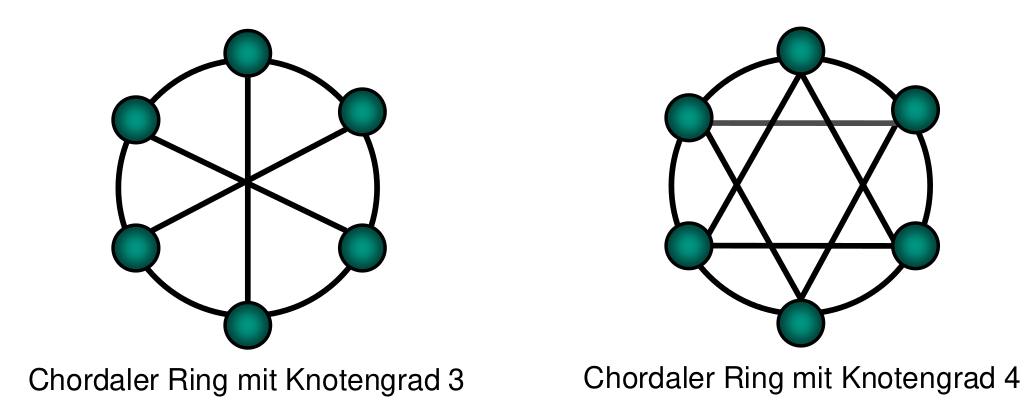
Chordaler Ring
- Hinzufügen redundanter Verbindungen
- Erhöht Fehlertoleranzeigenschaft des Verbindungsnetzwerkes
- Höherer Knotengrad und kleinerer Diameter gegenüber Ring
Baumstrukturen
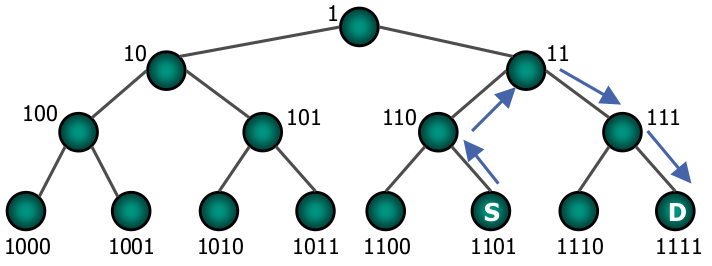
Einfacher Baum
- Finde gemeinsamen Elternknoten P von S und D
- Gehe von S nach P und von P nach D
Fat Tree
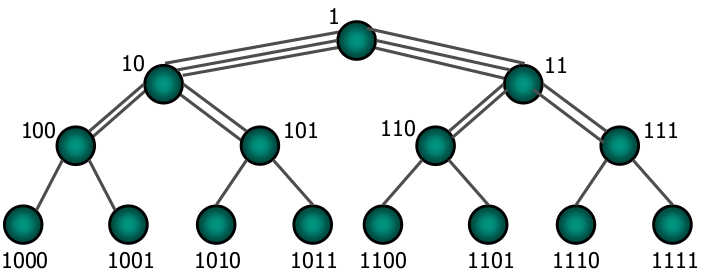
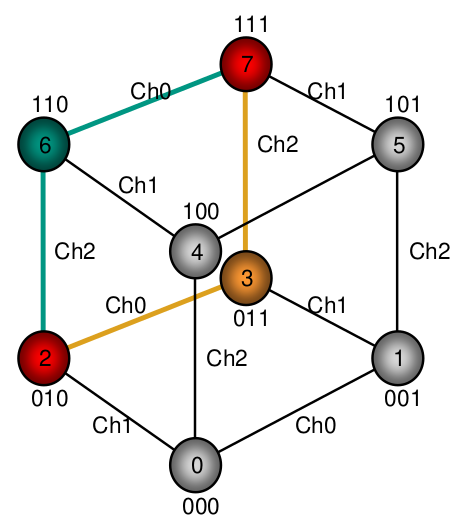
Hyperkubus
Die Knotennummern werden als Binärzahlen geschrieben, dadurch unterscheiden sich benachbarte Knoten in genau einer Stelle, die zudem die Richtung der Verbindung angeben kann (Hamming Distanz)
Pro Ecke sind Knoten im Bild unten also zwei pro „Kreis“
Dynamische Verbindungsnetzwerke
Geeignet für Anwendungen mit variablen und nicht regulären Kommunikationsmustern
Kreuzschienenverteiler (Crossbar)
- Vollständig vernetztes Verbindungswerk mit allen möglichen Permutationen der N Einheiten, die über das Netzwerk verbunden werden
- Alle angeschlossenen Prozessoren können paarweise disjunkt gleichzeitig und blockierungsfrei miteinander kommunizieren.
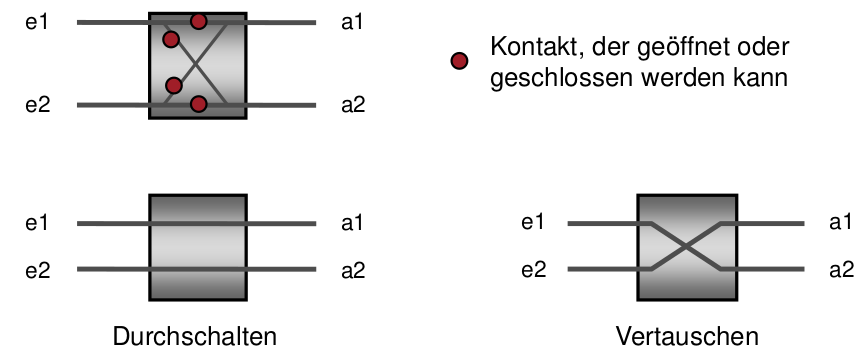
Schalterelemente (2x2 Kreuzschienenverteiler)
Bestehen aus Zweierschaltern mit zwei Eingängen und zwei Ausgängen, die entweder durchschalten oder die Ein- und Ausgänge überkreuzen können
Permutationsnetze
Einstufige Permutationsnetze
Enthalten eine einzelne Spalte von Zweierschaltern
Mehrstufige Permutationsnetze
Enthalten mehrere Spalte von Zweierschaltern
Reguläre Permutationsnetzwerke
p Eingänge, p Ausgänge und k Stufen mit jeweils p/2 Zweierschaltern, wobei die Zahl p normalerweise eine Zweierpotenz ist
Irreguläre Permutationsnetzwerke
Weisen gegenüber der vollen regulären Struktur Lücken auf
Kreuzpermutation K (Butterfly)
Abwechseln Bit tauschen und nicht
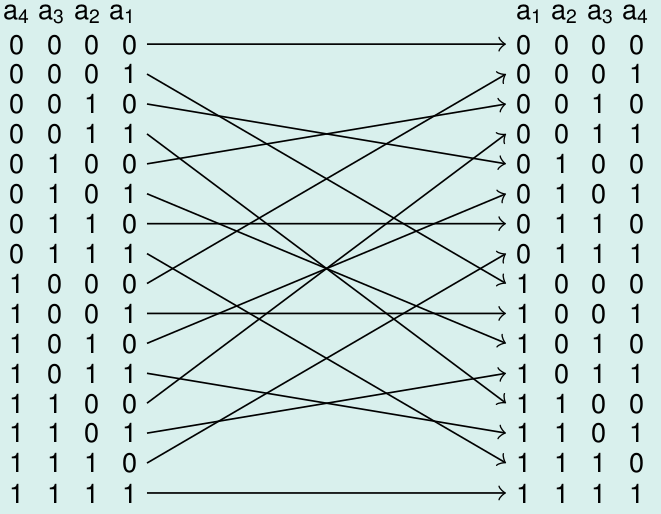
Tauschpermutation T (Butterfly)
Negation des niedrigwertigen Bits
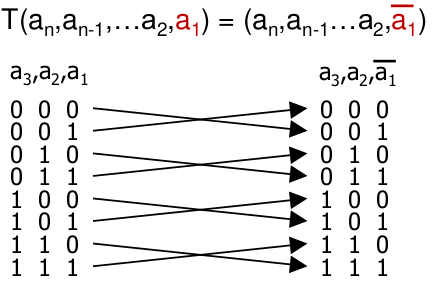
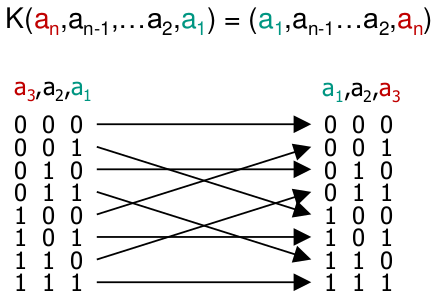
Umkehrpermutation U
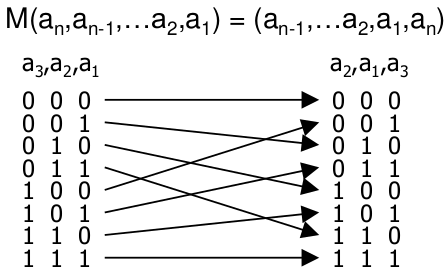
Mischpermutation M (Perfect Shuffle)
Rotate left
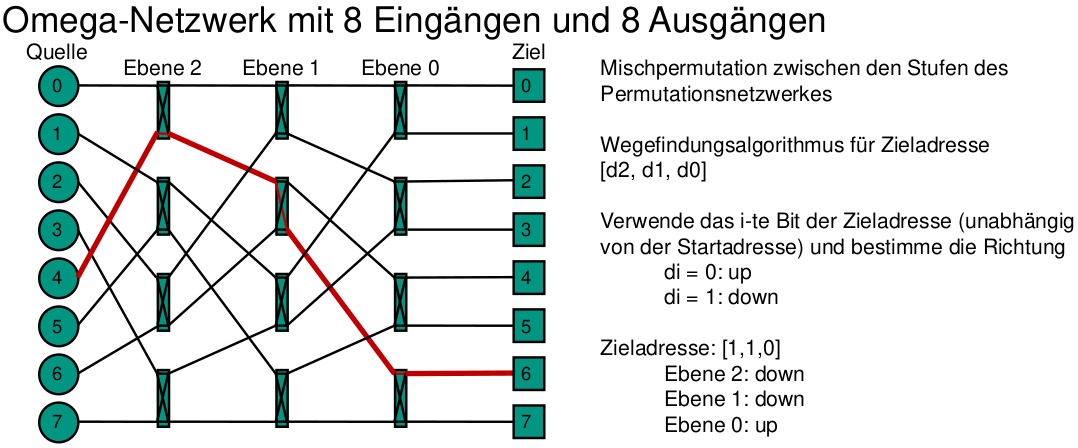
Omega-Netzwerk
Wo befindet sich die Steuerung des Verbindungsaufbaus bei dynamischen Verbindungsstrukturen?
Die Steuerung des Verbindungsaufbaus ist bei dynamischen Verbindungsstrukturen im Schaltnetz konzentriert.
Charakterisierung von Verbindungsnetzwerken
Latenz
- Sender overhead:
- Zusammenstellen des Pakets und Ablegen in Sendepuffer der Netzwerkschnittstelle
- Time of flight:
- Zeit, um ein Bit von der Quelle zum Ziel zu senden, wenn Weg festgelegt und konfliktfrei
- Transmission time
- Zusätzliche Zeit, die benötigt wird, alle Bits eines Pakets zu übertragen, nachdem erstes Bit beim Empfänger angekommen ist
- Hängt von Linkbandbreite ab
- Phit (physical transfer unit): Informationseinheit, die in einem Zyklus auf einem Link übertragen wird
- Routing time:
- Zeit, um den Weg aufzusetzen, bevor ein Teil des Pakets übertragen werden kann
- Switching time:
- Hängt von der Switching-Strategie ab
- Receiver overhead:
- Ablegen der Verwaltungsinformation und Weiterleiten des Pakts aus dem Empfangspuffer
- Sender overhead:
- Durchsatz oder Übertragungsbandbreite
Bisektionsbandbreite
Maximale Anzahl von Megabytes pro Sekunde, die das Netzwerk über die Bisektionslinie, die das Netzwerk in zwei gleiche Hälften teilt, transportieren kann
- Radius
- Durchmesser
- Verbindungsgrad
- Mittlere Distanz
- Erweiterbarkeit
- Skalierbarkeit
- Komplexität oder Kosten
Verbindungsstrukturen QPI
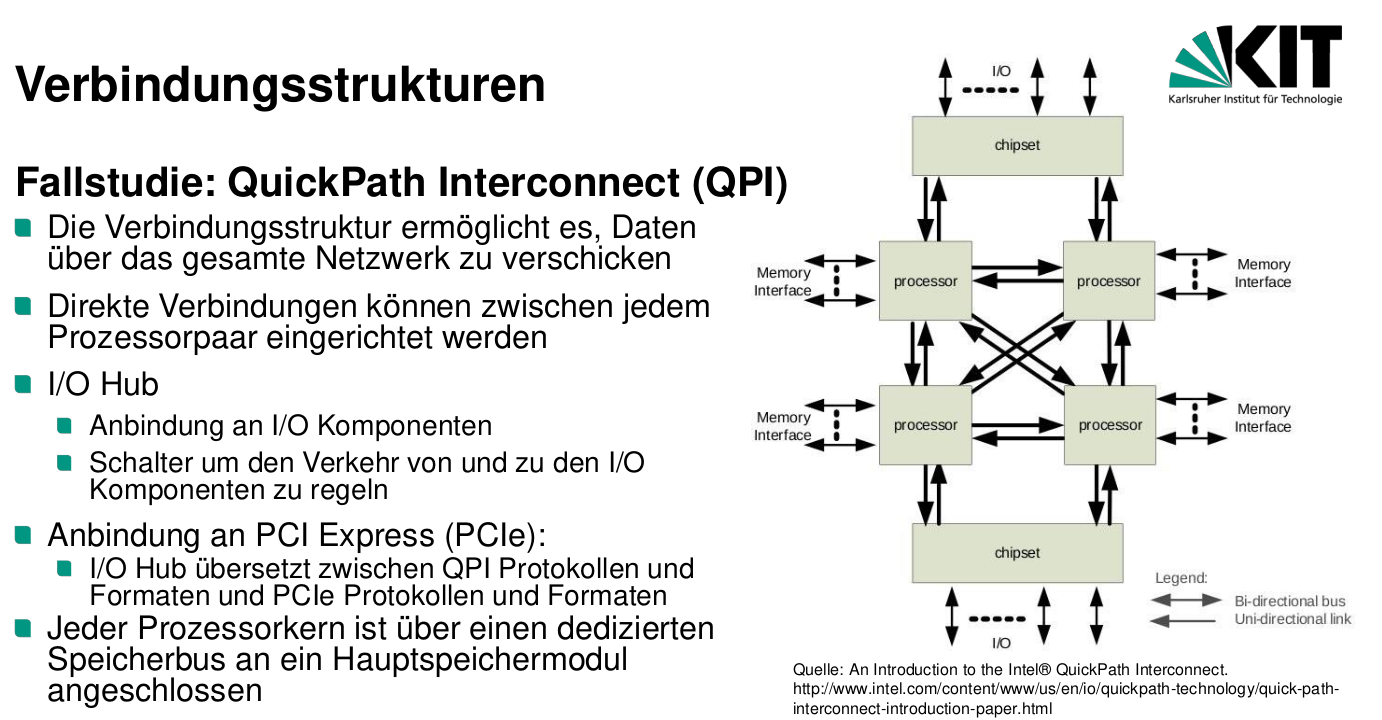
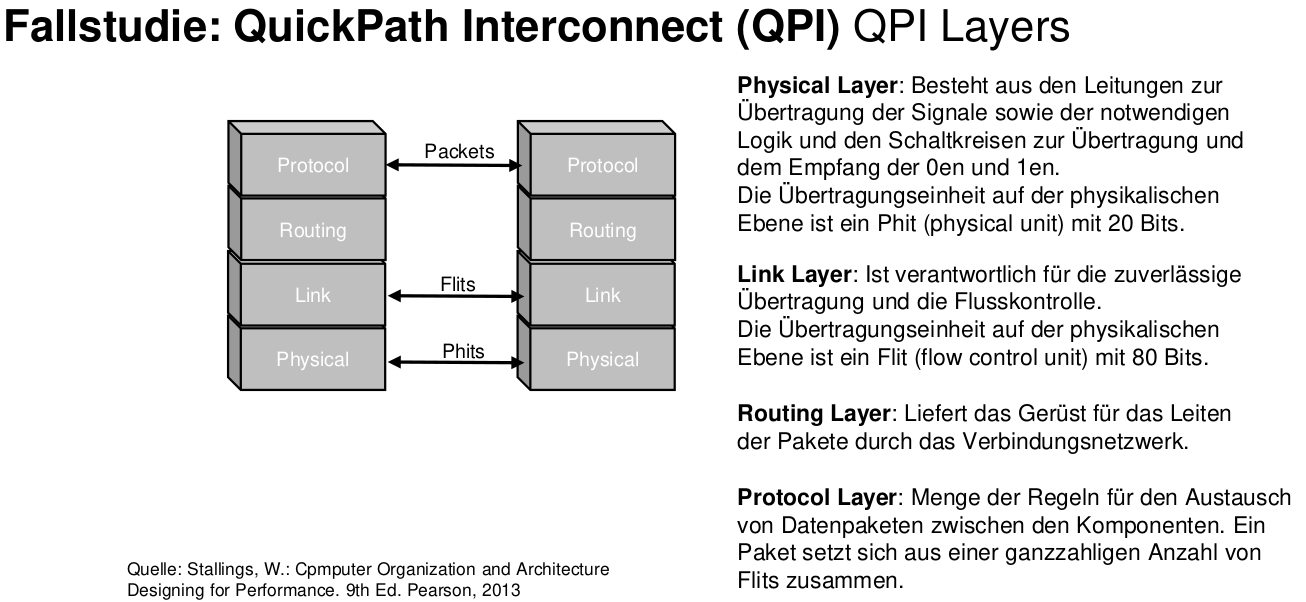
QPI Layer
Speichergekoppelte Multiprozessoren
Caches
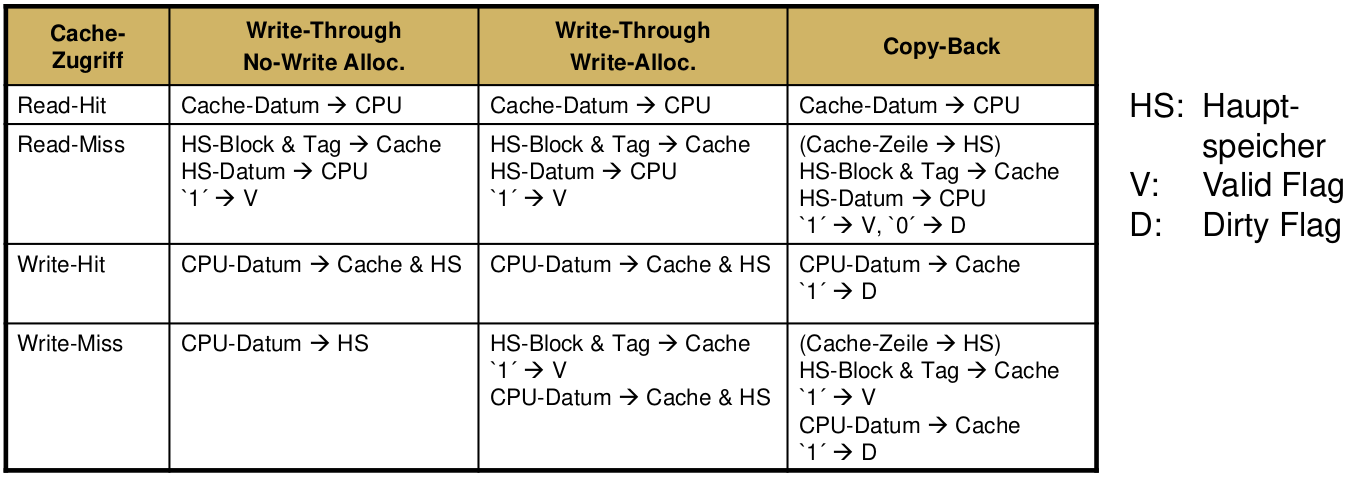
Cache-Speicher: Aktualisierungsstrategien
Cache-kohärent
- Eine Cache-Speicherverwaltung heißt Cache-kohärent, wenn ein Lesezugriff immer den Wert des zeitlich letzten Schreibzugriffs auf das entsprechende Speicherwort liefert
- Der Prozessor hat dann eine Cache-kohärente Sicht auf den Hauptspeicher
Kohärenz vs. Konsistenz
- Kohärenz
- Definiert, welcher Wert bei einem Lesezugriff geliefert wird
- Konsistenz
- Bestimmt, wann ein geschriebener Wert für einen Lesezugriff sichtbar wird
- Kohärenz
Mittlere Zugriffszeit einer Cachestufe
Mittlere Zugriffszeit zwei Cachestufen bei parallelem Zugriff
Mittlere Zugriffszeit zwei Cachestufen bei sequentiellem Zugriff
Vorteil und Nachteil von parallelem Cachezugriffen
- Vorteil: Bei einem Miss muss nicht zuerst gewartet werden, bis Zugriff auf höhere Ebene durchgeführt wurde (geringere Zugriffszeit)
- Nachteil: Bei einem Hit in einem der Caches wurde zuvor trotzdem eine Anfrage an Hauptspeicher gestartet, die dann abgebrochen wird. Der Bus wird also unnötigerweise blockiert.
Arten von Cache Misses
- Compulsory Miss
- Capacyity Miss
- Conflict Miss
- Set zu klein und bereits gecachtes Datum wurde aus Set entfernt (Cache nicht zwangsläufig voll)
- Nur bei nicht-vollassoziativem Cache
- Coherency Miss
- Nur bei Multiprozessor-Systemen mit Kohärenzprotokoll
- Unterscheidung zwischen False- und True-Sharing
- False-Sharing, falls nicht eigentliches Wort sondern anderes Wort in Cache-Block geändert wurde
Arten von Kohärenzprotokollen
Bus-Snooping-basiert
Write-Invalidate Protokoll
- arbeitet auf Cacheline-Ebene
- benötigt nur ein Invalidate
- Vertreter
- MSI
- MESI
- MOESI
Write-Update Protokoll
- arbeitet auf Wort-Ebene
- u. U. mehrere Update-Broadcasts nötig
Verzeichnisbasiert
MESI-Zustandsautomat
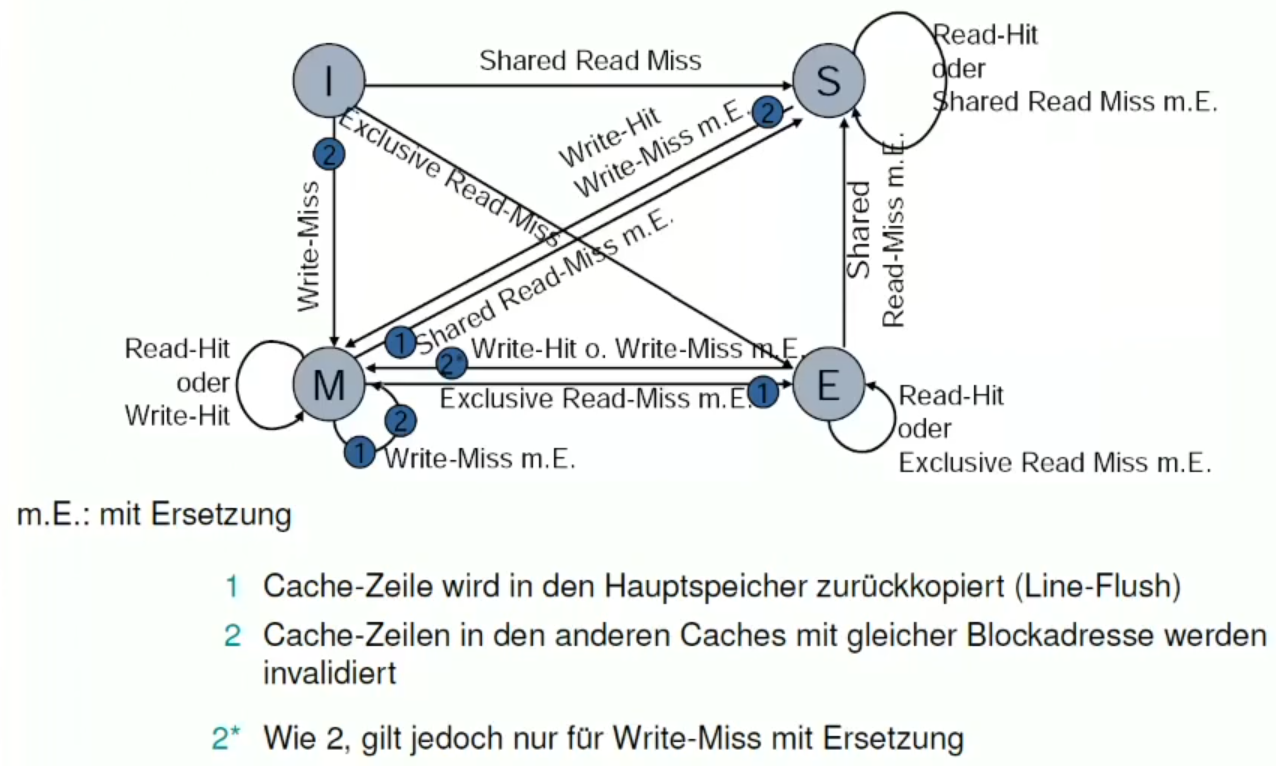
MESI Signale
- Invalidate-Signal
- Invalidieren von bestimmten Einträgen in den Caches aller anderer Prozessoren
- Shared-Signal
- Zeigt an, dass ein zu ladender Block bereits als Kopie vorhanden ist
- Retry-Signal
- Aufforderung für einen Prozessor, das Laden eines Blockes abzubrechen, da es modifiziert in einem anderen vorliegt
- Das Laden wird dann wieder aufgenommen, wenn ein anderer Prozessor aus dem Cache in den Hauptspeicher zurück geschrieben hat
- Invalidate-Signal
MOESI
Es gibt einen Owned Zustand in falls es zuvor Modified war und dann von einem anderen Prozess gelesen wird
Weitere Rechnerstrukturen
Warehouse-scale Computers
Anwendungsbereich Warehouse-scale Computers
- Internet Dienste
- Z.B. Suche, Social Networking, Online Karten, Video Sharing, Online Shopping, Email, Cloud Computing, etc.
Abgrenzung WSC von HPC
- HPC-Systeme (Cluster) haben leitungsfähigere Prozessoren und Verbindungsnetzwerke
- HPC-Systeme (Cluster) nützen Parallelismus auf Prozess-/Thread-Ebene (thread- level parallelism), WSCs sind auf “Request-level Parallelismus” ausgerichtet
Abgrenzung WSC von Datacentern
- Datacenters haben verschiedene Maschinen und Software an einem Standort
- Datacenters arbeiten mit virtuellen Maschinen und heterogener Hardware um verschiedene Kunden bedienen zu können
Entwurfsfaktoren für WSC
- Preis-Leistung
- Skalierung: Schon wenige Einsparungen wirken sich auf die Kosten aus
- Energieeffizienz
- Wirkt sich auf die Stromversorgung und Kühlung aus
- „Arbeit“ pro Joule
- Zuverlässigkeit mit Hilfe von Redundanz
- Netzwerk I/O
- Interaktive- und Batch-Arbeitslasten
- Ausnützen des Parallelismus bei Berechnungen hat nicht die Bedeutung
- Die meisten Jobs sind unabhängig voneinander
- „Request-level Parallelismus“
- Betriebskosten
- Niedriger Energieverbrauch ist eines der wichtigsten Entwurfsziele
Standort
Nähe zu Interbackbones, Elektrizitätskosten, Steuern, niedrige Gefährdung durch Naturkatastrophen
- Effiziente Berechnungen bei nicht voller Auslastung
- Preis-Leistung